「ChatGPTに社内規程のことを聞いても答えられない」「AIに最新情報や自社ドキュメントをふまえて回答してほしい」——生成AIを業務に導入しようとすると、必ずこの課題に行き着きます。その答えがRAGです。
この記事では、RAG(検索拡張生成)の仕組みを4ステップで整理し、心臓部であるベクトルデータベース、発展形、ファインチューニングとの使い分けまでを非エンジニア向けに解説します。内容は、当スクールが法人研修・オンラインコースで実際に使っている基礎講義(Foundation)をベースにしています。
生成AIそのものの基礎は 生成AIとは?法人の業務自動化ガイド を先に読むと理解がスムーズです。
この記事でわかること
- RAGとは何か・なぜ必要か(RAGなしのLLMが抱える4つの問題)
- RAGの4ステップ — Ingestion → Retrieval → Augmentation → Generation
- ベクトルデータベースとは — キーワード検索と意味検索の違い
- 主要なベクトルDB6種の比較と初心者へのおすすめ
- RAGの発展形(Agentic RAG・Hybrid RAG・Graph RAG・Multimodal RAG)
- RAG vs ファインチューニング — 使い分けの判断基準
- RAGが有効な業務ケース
RAGとは — 教科書持ち込み可の試験
RAG(Retrieval-Augmented Generation:検索拡張生成)とは、「検索(Retrieval)」によって取得した情報でLLMの生成を「拡張(Augmented)」する技術です。この概念は Lewis et al., 2020 の論文 "Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks" で初めて体系的に提案されました。
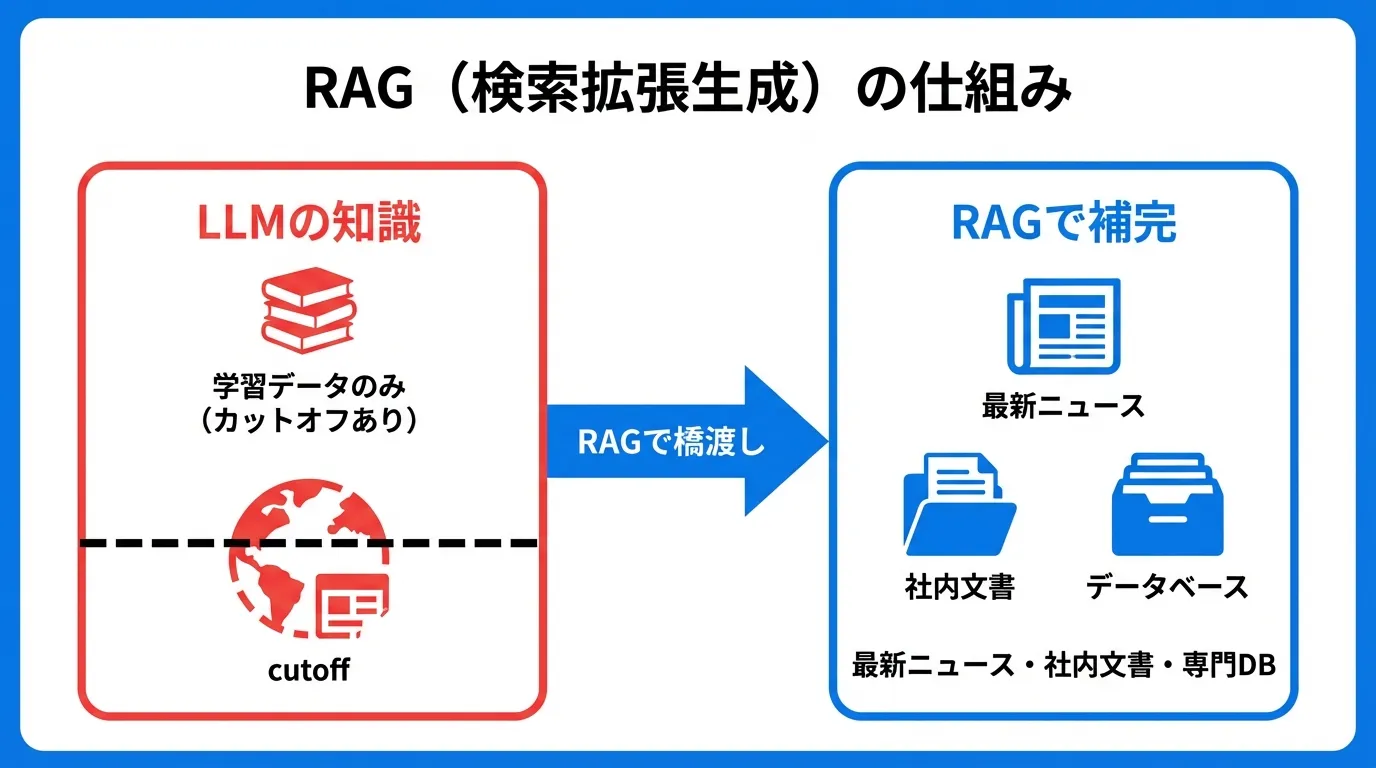
たとえるなら、RAGは「教科書持ち込み可の試験」です。通常のLLMは暗記した知識だけで回答する試験ですが、RAGを使うと質問に関連する資料をデータベースから探してきて、それを見ながら回答できます。だから最新情報や社内ドキュメントなど、LLMが学習していない情報にも正確に答えられるのです。
RAGなしのLLMが抱える4つの問題
| 問題 | 内容 |
|---|---|
| 知識のカットオフ | 学習後の情報を知らない |
| ハルシネーション | 知らないことを捏造する |
| プライベート情報 | 社内文書などは学習していない |
| 更新困難 | 新情報を追加するには再学習が必要 |
RAGはこの4つを裏返しで解決します。最新情報はデータベースを更新するだけで反映でき、出典付きで回答できるため正確性が向上し、社内文書も検索対象にでき、モデル再学習よりコスト効率が高い——これがRAGのメリットです。ハルシネーションの構造的な原因と対策は ハルシネーションとは?原因と対策 で詳しく解説しています。
RAGの4ステップ
RAGは大きく4つのステップで動作します。
- Ingestion(取り込み) — 社内文書などのデータをベクトルDBに格納する準備段階。データを取り込み、ベクトル化する
- Retrieval(検索) — ユーザーの質問に関連する情報をデータベースから取得する
- Augmentation(拡張) — 検索結果をプロンプトに組み込む
- Generation(生成) — LLMが拡張されたプロンプトをもとに回答を生成する
ポイントは、LLM自体には一切手を加えていないことです。変わるのは「LLMに渡す情報(コンテキスト)」だけ。だからモデルの再学習なしに、自社固有の知識をAIに使わせることができます。コンテキストにどんな情報が入るかの全体像は トークン・コンテキストウィンドウ入門 も参考にしてください。
ベクトルデータベース — RAGの心臓部
RAGの心臓部となるのが**ベクトルデータベース(Vector DB)**です。
通常のデータベースは「著者名」「出版日」など正確なキーワードで検索します。これに対しベクトルDBは「意味が近いもの」で検索できます。「楽しい」で検索すると「嬉しい」「ハッピー」も見つかる——これが「意味検索(Semantic Search/セマンティック検索)」です。
| 観点 | キーワード検索 | セマンティック検索 |
|---|---|---|
| マッチの仕方 | 完全一致のみ | 意味が近い語もヒット |
| 例 | 「犬」で検索 → 「犬」を含む文書のみ | 「犬」で検索 → 意味的に近い文書もヒット |
| 仕組み | 文字列の一致 | ベクトル空間上の距離(意味が近い語は近くに配置される) |
主要なベクトルDBの比較
| DB名 | 特徴 | 用途 |
|---|---|---|
| Pinecone | フルマネージド、高速、スケーラブル | 本番環境、大規模データ |
| Chroma | 軽量、ローカル実行可、Python親和性 | 開発・プロトタイプ |
| Weaviate | GraphQL対応、ハイブリッド検索 | 複雑なクエリ |
| Milvus | オープンソース、高性能 | オンプレミス大規模 |
| Qdrant | Rust製、高速フィルタリング、豊富なAPI | 高性能検索、フィルタ付き検索 |
| pgvector | PostgreSQLの拡張、SQLで操作可能 | 既存PostgreSQLに追加 |
初心者にはまず Chroma から始めるのがおすすめです。ローカルで簡単に試せて、Pythonからすぐに使えます。本番環境に移行する際は Pinecone や pgvector を検討しましょう。
RAGの発展形(上級者向け)
基本のRAGを押さえた後の発展内容として、4つのバリエーションがあります。
| 発展形 | 概要 | 強み |
|---|---|---|
| Agentic RAG | AIエージェントが検索を計画・実行。複数回の検索を自律的に行い、結果を評価して追加検索 | 複雑な質問に対応 |
| Hybrid RAG | ベクトル検索+キーワード検索の組み合わせ | 固有名詞に強く、精度と再現率のバランス向上 |
| Graph RAG | 知識グラフと組み合わせ、エンティティ間の関係性を活用 | 「AとBの関係は?」に強く、複雑な推論が可能 |
| Multimodal RAG | テキストに加え画像・動画も検索対象 | 「この画像に似た製品は?」、文書内の図表も対象 |
まずは基本の4ステップRAGを動かし、固有名詞の検索精度に課題が出たらHybrid、関係性の質問が多ければGraph、と段階的に検討するのが現実的です。
RAG vs ファインチューニング — 使い分け
どちらもLLMをカスタマイズする方法ですが、用途が異なります。ファインチューニングは、既存のモデルを特定のタスクや文体に合わせて追加学習する手法です。
| 観点 | RAG | ファインチューニング |
|---|---|---|
| 目的 | 外部知識を参照させる | モデルの振る舞いを変える |
| 更新の容易さ | ◎ DB更新だけ | △ 再学習が必要 |
| コスト | ◎ 低い | △ 従来は高かったが、LoRA/QLoRAなどの手法で大幅に低下 |
| レイテンシー(応答時間) | △ 検索処理が追加 | ◎ 追加処理なし |
| 出典の明示 | ◎ 可能 | × 困難 |
| 適した用途 | FAQ、ドキュメント検索、最新情報 | トーン変更、ドメイン特化 |
選び方の基準はシンプルです。
- 最新情報や社内文書を参照したい → RAG
- 出典を明示したい → RAG
- AIの話し方やスタイルを変えたい → ファインチューニング
- 両方必要 → 組み合わせ(ファインチューニング済みモデル + RAG)
RAGが有効な業務ケース
- 社内ドキュメントのQ&A — 規程・マニュアル・過去事例への質問応答
- 最新情報が必要な回答 — 学習データのカットオフ後の情報を扱う業務
- 出典を明示したい場合 — 「この回答は規程◯◯に基づく」と示したい監査性の高い業務
- 頻繁に情報が更新される場合 — 製品情報・価格表・FAQなど更新サイクルが速いデータ
導入の進め方としては、まず対象ドキュメントを1種類(社内FAQなど)に絞って小さく始め、回答品質と出典の正しさを検証してから対象を広げるのが定石です。チームでまとめて習得したい場合は 法人向けAIエージェント研修 でハンズオン形式の導入が可能です。
よくある質問
Q. RAGとは何ですか?一言でいうと? A. RAG(Retrieval-Augmented Generation:検索拡張生成)とは、質問に関連する情報を外部データベースから検索(Retrieval)し、その情報でLLMの回答生成を拡張(Augmented)する技術です。「教科書持ち込み可の試験」にたとえられ、LLMが学習していない最新情報や社内文書にも、資料を見ながら正確に答えられるようになります。
Q. なぜ普通のChatGPTでは社内文書に答えられないのですか? A. LLMの知識は学習時点のデータに限られるためです(知識のカットオフ)。社内規程や顧客データのようなプライベート情報はそもそも学習されておらず、知らないことを聞かれると捏造(ハルシネーション)するリスクもあります。RAGなら社内文書をベクトルDBに取り込み、質問のたびに関連箇所を検索して回答に使うため、再学習なしで自社知識に答えられます。
Q. ベクトルデータベースは普通のデータベースと何が違いますか? A. 検索の仕方が違います。通常のDBは「完全一致するキーワード」で検索しますが、ベクトルDBはテキストを数値ベクトルに変換し、「意味が近いもの」を検索できます(セマンティック検索)。たとえば「楽しい」で検索すると「嬉しい」「ハッピー」を含む文書もヒットします。質問の言い回しと文書の言い回しが違っても関連情報を見つけられるため、RAGの検索ステップに不可欠です。
Q. RAGとファインチューニングはどちらを選ぶべきですか? A. 目的で分けます。最新情報や社内文書を参照させたい、出典を明示したい場合はRAGです。データベースの更新だけで知識を更新でき、コストも低く済みます。一方、AIの話し方・文体・ドメイン特化の振る舞いそのものを変えたい場合はファインチューニングです。両方必要なら、ファインチューニング済みモデルにRAGを組み合わせる構成も可能です。
Q. 小さく始めるなら何から着手すべきですか? A. 開発・プロトタイプ向きの軽量ベクトルDB(Chromaなど)を使い、社内FAQのような1種類のドキュメントに絞ってRAGの4ステップを動かすのが最短です。回答に出典を表示させ、正しい文書を参照できているかを検証してから、対象ドキュメントを広げます。本番運用の段階でPineconeやpgvectorのようなスケールに強い選択肢を検討しましょう。
関連記事
- 生成AIとは?法人の業務自動化・AIエージェント活用ガイド
- ハルシネーションとは?原因・種類と対策
- トークン・コンテキストウィンドウ入門
- プロンプトエンジニアリングとは?実践入門
- 法人向けAIエージェント研修(ハンズオン)
最終確認日: 2026-06-10