「AIの利用料金がなぜこの金額なのか分からない」「会話が長くなるとAIが最初の指示を忘れる」——この2つの疑問は、どちらもトークンとコンテキストウィンドウという同じ仕組みで説明できます。
この記事では、LLMの容量とコストを決めるこの2つの概念を基礎から解説し、業務でコストを抑えながら出力品質を保つ実践テクニックまでをまとめます。内容は、当スクールが法人研修・オンラインコースで実際に使っている基礎講義(Foundation)をベースにしています。
生成AIの仕組み全体(次トークン予測など)は 生成AIとは?法人の業務自動化ガイド を先に読むと理解がスムーズです。
この記事でわかること
- トークンとは何か — LLMがテキストを処理する最小単位
- なぜトークン化が必要か — テキストからIDへの変換フロー
- トークン数の目安 — 日本語は英語より「割高」
- 入力トークン vs 出力トークン — 料金の仕組みと計算例
- コンテキストウィンドウとは — 主要モデルの上限比較
- AIが「指示を忘れる」理由 — コンテキストの中身とCompaction
- トークン使用量を最適化する6つのテクニックとセルフチェック
トークンとは — LLMがテキストを処理する最小単位
トークンとは、LLM(大規模言語モデル)がテキストを処理するための最小単位です。LLMは文章を単語や文字のかたまり(トークン)に分割してから処理します。
- 英語の場合: "Hello, world!" → ["Hello", ",", " world", "!"](約4トークン)
- 日本語の場合: 「こんにちは」 → ["こん", "にち", "は"](約3トークン。モデルにより異なる)
重要なポイントは3つあります。
- 日本語は英語よりトークン効率が悪い — 同じ意味でもより多くのトークンを消費します
- 1トークン ≒ 英語で約4文字、日本語で約1〜2文字が目安です
- コードや記号も独自のトークン化ルールがあります
なぜトークン化が必要か
コンピュータは文字をそのまま理解できません。テキストを数値に変換する必要があります。
- テキスト: "Hello AI"
- トークン化: ["Hello", " AI"]
- ID変換: [15496, 9552]
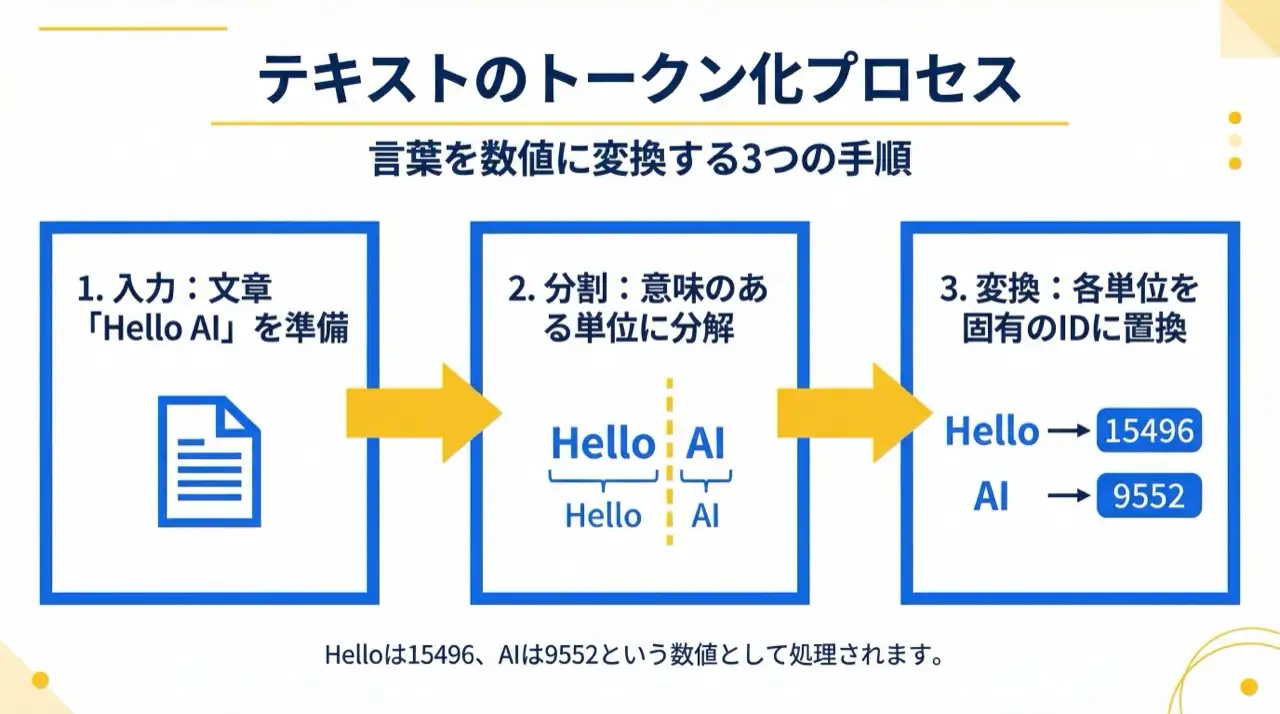
各トークンには一意のID(数字)が割り当てられ、このIDがモデルの入力として使用されます。つまりLLMは「単語の意味」ではなく**「トークンIDのパターン」を学習している**のです。
トークン数の概算目安
| テキスト量 | トークン数の目安 |
|---|---|
| 英語 1,000語 | 約750トークン |
| 日本語 1,000文字 | 約500〜700トークン |
| コード 100行 | 約500〜1,500トークン |
APIを使う前にトークン数を確認すれば、コストを予測できます。
入力トークン vs 出力トークン — 料金の仕組み
LLMの利用料金は「入力トークン+出力トークン」の合計で決まり、両者で単価が異なります。
| 区分 | 含まれるもの | 料金目安 |
|---|---|---|
| 入力トークン | ユーザーのプロンプト、システムプロンプト、会話履歴、添付ファイルの内容 | 比較的安価 |
| 出力トークン | AIの応答テキスト、生成されたコード、回答全体 | 入力より高価(2〜8倍) |
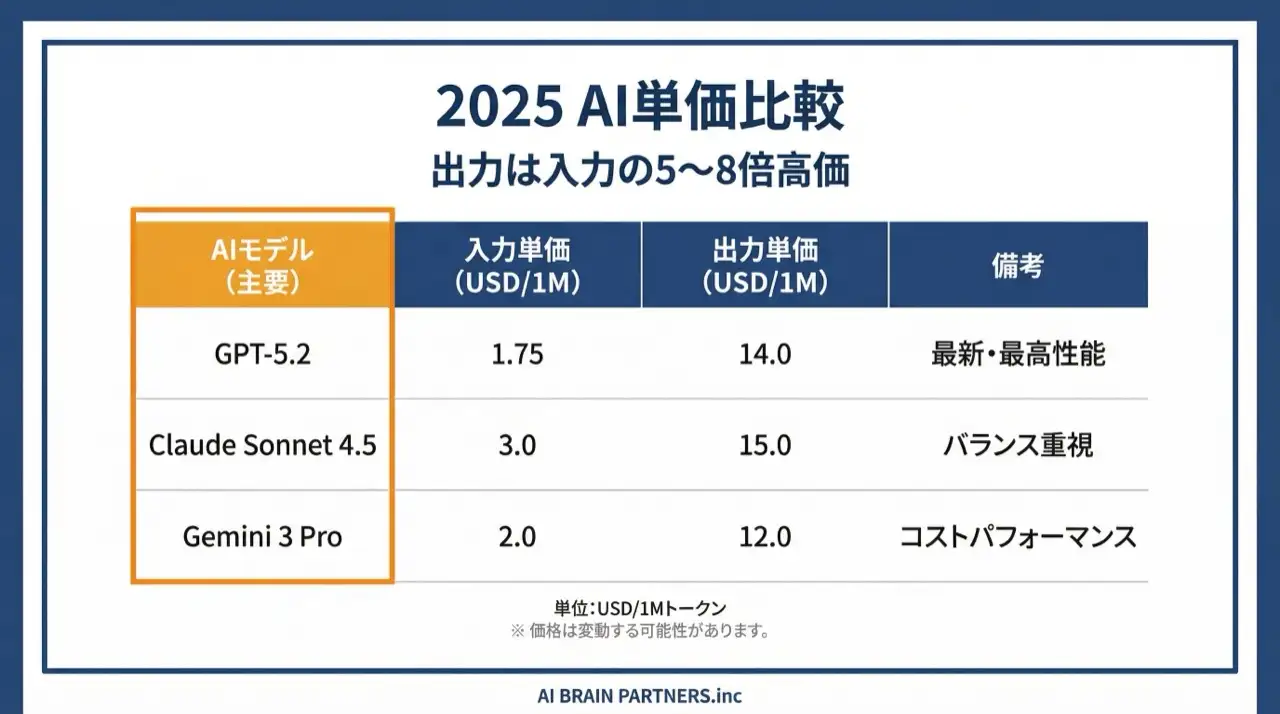
教材で扱っている料金計算の例(GPT-5.2・2026年)です。
- 入力: 1,000トークン × $1.75/1M = $0.00175
- 出力: 500トークン × $14/1M = $0.007
- 合計: 約$0.009(約1.5円)/ 1リクエスト
1回あたりは小さくても、チームで毎日数百回使えば無視できない金額になります。出力形式を指定して出力トークンを抑えるのが最も効果的な節約策である理由がここにあります。
コンテキストウィンドウとは — 一度に扱える上限
コンテキストウィンドウとは、LLMが一度に処理できる最大トークン数です。主要モデルの比較です(教材2026年版より)。
| モデル | コンテキストウィンドウ | 目安 |
|---|---|---|
| GPT-5.2 | 400K tokens | 小説約3冊分 |
| Claude Sonnet 4.6 | 200K tokens(1M Beta) | 小説約1.5冊分 |
| Gemini 3 Pro | 1M tokens | 小説約7冊分 |
| Llama 4 Scout | 10M tokens | 小説約70冊分 |
| DeepSeek-V3.2 | 128K tokens | 小説約1冊分 |
コンテキストウィンドウが重要な理由は3つです。
- 長い会話や大きなファイルを処理するときの制限になる
- ウィンドウを超えると古い情報が「忘れられる」
- 大きなコンテキストウィンドウ = より多くの情報を一度に扱える
AIが「指示を忘れる」理由 — コンテキストの中身
「丁寧に指示したのに、途中からAIが指示を無視し始めた」——この現象の正体もコンテキストウィンドウにあります。
重要な前提は、AIは会話を「記憶」していないことです。チャットボックス(コンテキストウィンドウ)には、毎回次の情報がすべて詰め込まれて渡されています。
- システムプロンプト — AIの基本設定・振る舞い
- ユーザープロンプト — 今の質問・指示
- Tool / MCP / Rules — 使えるツール、外部接続、プロジェクトルール
- ドキュメント(RAG系) — 検索で取得した参考資料
- 過去の会話履歴 — チャットのやり取り全部
セッションを閉じればAIは忘れます。長期記憶が必要な場合は、Memory機能やファイルへの書き出しで明示的に保存する必要があります。
Compaction(圧縮)— 満杯になったら何が起きるか
会話が長くなりコンテキストウィンドウの上限に近づくと、**Compaction(圧縮)**が発生し、古い会話が要約・削除されます。空きはできますが、情報は失われます。「最初に伝えた指示をAIが忘れた」と感じる現象の多くはこれが原因です。
規模感の例として、1,000行のファイルを1回読むと約4,000トークンを消費します。30ファイル読んで20回コマンドを実行すれば10万トークン超になることもあり、圧縮なしでは大規模な作業は回りません。
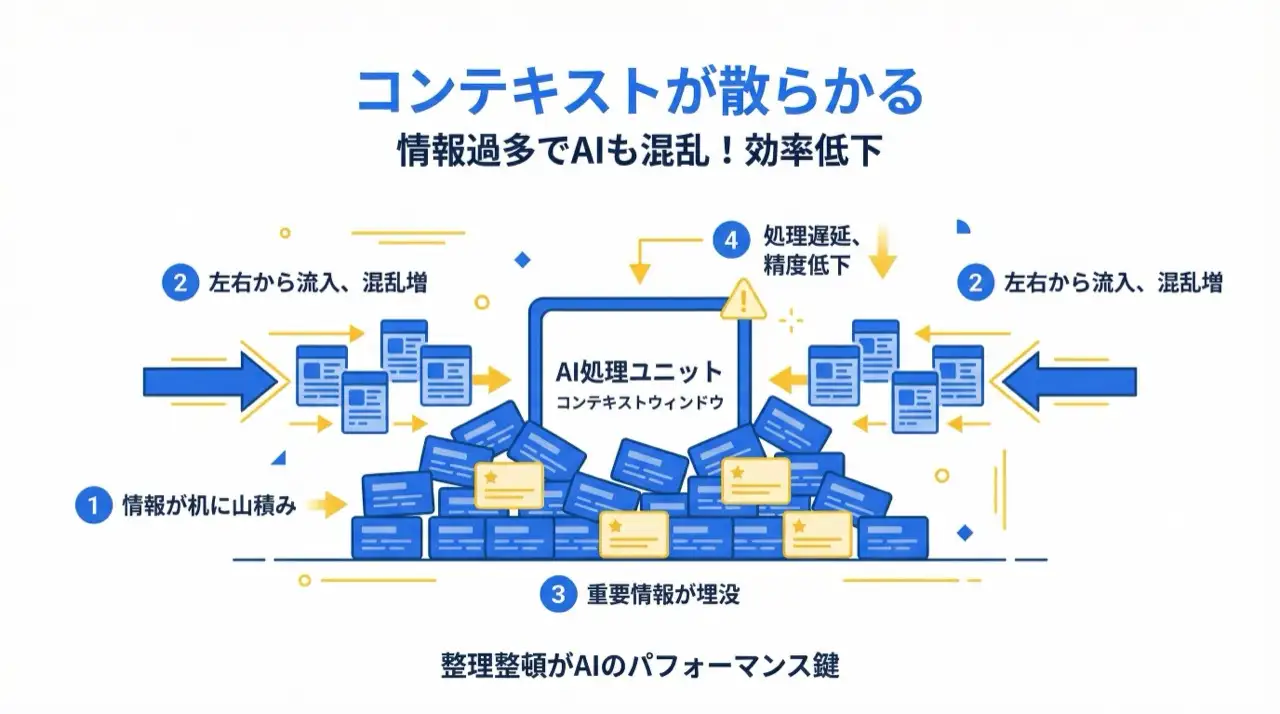
コンテキストに様々な情報が入り込むと、散らかった机のように情報過多でAIも混乱します。コンテキストを綺麗に保つことが、AIの出力品質を維持する最も簡単な方法です。対策はシンプルで、タスクごとに新しいセッション(New Agent)を開始し、重要な決定はファイルに書き出しておくことです。
トークン使用量を最適化する6つのテクニック
| テクニック | 内容 | 例 |
|---|---|---|
| 1. 簡潔なプロンプト | 冗長な説明を避け、要点を絞った指示にする | NG:「〜してください。もし可能であれば…」→ OK:「〜を実行」 |
| 2. 必要な情報のみ | 大きなファイルは関連部分だけ抽出して渡す | 全ファイルではなく該当関数・セクションのみ |
| 3. 出力形式を指定 | 必要な形式を明示して無駄な説明を防ぐ | 「JSON形式でkeyのみ出力」「箇条書きで5項目以内」 |
| 4. 会話履歴の管理 | 長い会話は要約してリセット | 20ターン以上の会話は要点をまとめて新しい会話へ |
| 5. 適切なモデル選択 | タスクの複雑さに応じて使い分け | 簡単なタスクは軽量モデル、複雑なタスクは高性能モデル |
| 6. 言語の考慮 | 英語の方がトークン効率が良い場合も | 技術的な指示は英語で書き、結果を日本語で求める |
コストが高いと感じたときのセルフチェック
教材のチェックリストから、特に効果の大きい項目を抜粋します。
- 1タスク=1チャットを守っているか — 無関係なタスクを1つの会話で続けると、不要なコンテキストが積み上がります
- 巨大ファイルを丸ごと添付していないか — 1,000行超のファイルはそれだけで4,000トークン以上を消費します。必要な範囲だけ指定しましょう
- 計画を立ててから実行しているか — 計画なしの試行錯誤は、読み直し・やり直しでトークンを2〜3倍消費します
- ルールファイルが肥大化していないか — ルールファイルは毎回コンテキストに読み込まれます。不要なルールは定期的に整理しましょう
- 出力量をコントロールしているか — 「詳しく説明して」は出力トークンを増やします。「簡潔に・箇条書きで」と形式を指定しましょう
まとめると、トークン消費 = 入力(コンテキスト)+出力(回答)の合計です。入力を小さく保ち、出力形式をコントロールすることで、同じ作業量でもコストを大幅に削減できます。指示の書き方そのものは プロンプトエンジニアリング実践入門 を、社内文書を効率よく参照させる方法は RAGとは?仕組み4ステップ を参考にしてください。
よくある質問
Q. トークンとは何ですか?文字数とは違うのですか? A. トークンはLLMがテキストを処理する最小単位で、文字数とは一致しません。英語では1トークン≒約4文字、日本語では1トークン≒約1〜2文字が目安です。概算では英語1,000語≒約750トークン、日本語1,000文字≒約500〜700トークンになります。日本語は英語よりトークン効率が悪く、同じ意味の文章でも多くのトークンを消費する点が、コスト管理上の重要なポイントです。
Q. なぜAIの料金は出力の方が高いのですか? A. LLMの料金体系は入力トークンと出力トークンで単価が分かれており、出力は入力の2〜8倍高価な設定が一般的です。たとえばGPT-5.2(2026年)では入力1,000トークン+出力500トークンで約$0.009(約1.5円)です。だからこそ「箇条書きで」「5項目以内で」と出力形式を指定して出力トークンを抑えることが、品質とコストの両方に効く最も手軽な最適化になります。
Q. AIが会話の途中で指示を忘れるのはなぜですか? A. AIは会話を記憶しておらず、毎回コンテキストウィンドウにシステムプロンプト・ルール・参照資料・過去の会話履歴をすべて詰めて処理しているためです。会話が長くなって上限に近づくとCompaction(圧縮)が発生し、古い会話が要約・削除されて情報が失われます。対策は、1タスク=1チャットで運用すること、長い会話は要点をまとめて新しいセッションに切り替えること、重要な決定はファイルに書き出すことです。
Q. コンテキストウィンドウは大きいほど良いのですか? A. 大きいほど多くの情報を一度に扱えますが、「大きいから何でも詰め込んでよい」わけではありません。不要な情報が増えるとAIが混乱して精度が落ち、入力トークンが増えてコストも上がります。モデル選択では上限(GPT-5.2は400K、Gemini 3 Proは1M、Llama 4 Scoutは10Mなど)を確認しつつ、実運用では「必要な情報だけを渡してコンテキストを綺麗に保つ」ことの方が出力品質に効きます。
Q. 今日からできる一番簡単なコスト削減策は何ですか? A. 出力形式の指定です。「箇条書きで5項目以内」「JSON形式でkeyのみ」のように形式を縛るだけで、単価の高い出力トークンを直接削減できます。次に効くのは、1タスク=1チャットの徹底と、巨大ファイルを丸ごと貼らずに必要な範囲だけ渡すことです。この3つはツールの設定変更なしに今日から実践でき、品質低下もありません。
関連記事
- 生成AIとは?法人の業務自動化・AIエージェント活用ガイド
- プロンプトエンジニアリングとは?実践入門
- RAGとは?仕組み4ステップとベクトルDB・活用法
- Skill・SubAgent・Agent TeamでAIエージェントを拡張する
- 法人向けAIエージェント研修(ハンズオン)
最終確認日: 2026-06-10