"La IA me dijo algo incorrecto con total seguridad." "Citó un artículo científico que no existe." Cualquiera que use IA generativa en el trabajo se encuentra tarde o temprano con este fenómeno. Se llama alucinación.
En esta guía explicamos de forma sistemática por qué ocurren las alucinaciones (cuatro causas), qué patrones adoptan (cuatro tipos) y cómo mitigarlas en la práctica. El contenido se basa en las lecciones fundamentales que usamos en nuestra formación corporativa y cursos online.
Qué aprenderás en este artículo
- Qué es una alucinación: una propiedad estructural, no un bug
- Por qué ocurren: las cuatro causas
- Los cuatro tipos de alucinación y por qué las citas inventadas son las más peligrosas
- Cuatro mitigaciones y un prompt concreto anti-alucinaciones
- Cómo convivir con las alucinaciones: verificar, cuestionar y aprovechar las fortalezas
- Dónde la IA es fuerte y dónde la verificación es obligatoria
Qué es una alucinación: una mentira verosímil
Una alucinación es el fenómeno por el cual un LLM (modelo de lenguaje de gran tamaño) genera información sin base factual pero que suena verosímil. Puede citar artículos que no existen o describir con detalle el perfil de una persona ficticia.
Hay una premisa crucial: los LLM no garantizan la exactitud. Incluso el modelo más potente afirmará a veces falsedades con total seguridad. No es un bug: es una propiedad estructural de su funcionamiento.
El cerebro humano ofrece una buena analogía. Nosotros también rellenamos los huecos de la memoria con información "que suena bien": afirmas con seguridad que una película se estrenó en 2015 cuando en realidad fue en 2017. Los LLM se comportan de forma parecida: ante información que no aprendieron o que conocen vagamente, generan una respuesta que simplemente "suena correcta".

Por qué ocurren las alucinaciones: cuatro causas
| Causa | Descripción |
|---|---|
| 1. Coincidencia de patrones estadísticos | Si los LLM "comprenden" en el sentido humano sigue siendo objeto de debate entre investigadores. En esencia aprenden patrones estadísticos — qué palabra tiende a seguir a cuál — y generan según lo que suena natural, no según lo que es correcto |
| 2. Problemas de los datos de entrenamiento | Los datos de internet contienen desinformación, y el modelo no sabe nada posterior a su corte de conocimiento |
| 3. Expresión insuficiente de la incertidumbre | Los primeros LLM apenas fueron entrenados para expresar incertidumbre. Técnicas como RLHF (aprendizaje por refuerzo con retroalimentación humana) lo han mejorado, pero los modelos siguen tendiendo a producir una respuesta antes que decir "no lo sé" |
| 4. Problemas de las métricas de evaluación | Cuando las "respuestas detalladas" puntúan bien, responder con concreción — aun sin certeza — tiende a premiarse, mientras que "no lo sé" puede penalizarse |
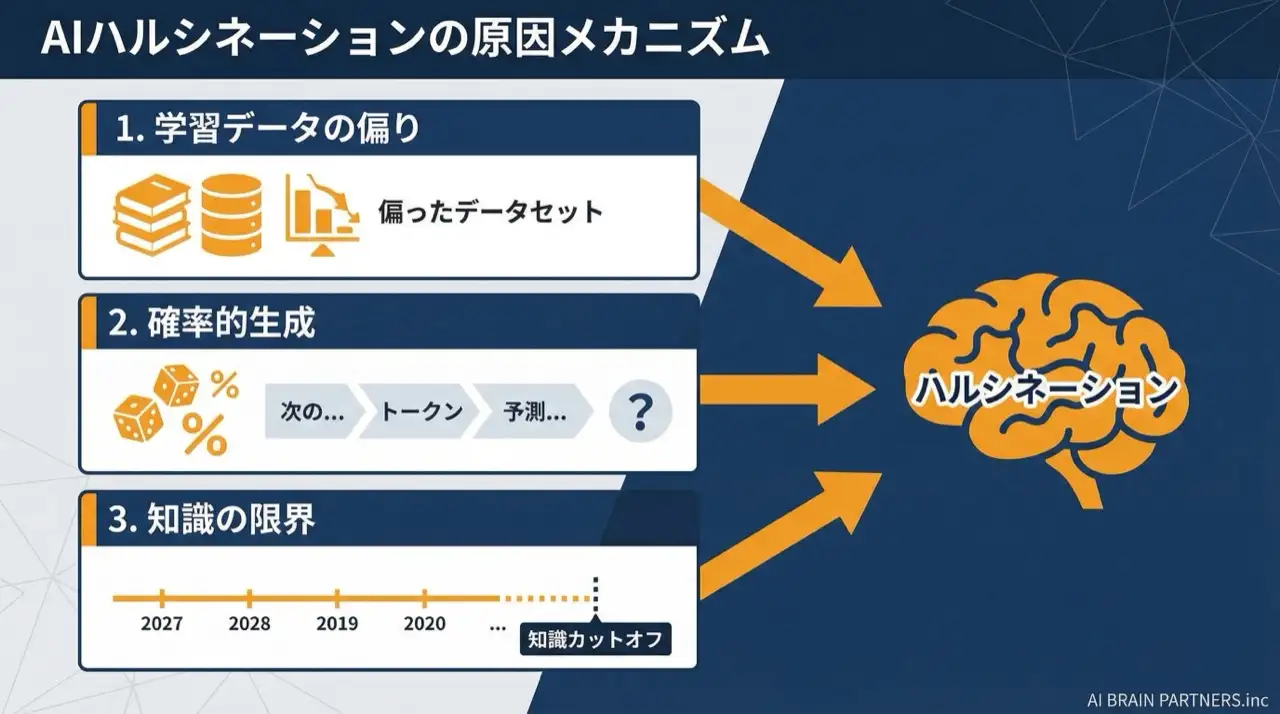
En otras palabras, la alucinación no es un defecto del modelo, sino un subproducto de un sistema optimizado para producir texto que suena natural. Por eso los modelos mejores la reducen, pero nunca la eliminan.
Los cuatro tipos de alucinación
| Tipo | Qué ocurre | Ejemplo |
|---|---|---|
| Invención de hechos | Crea hechos que no existen | "La Torre de Tokio se construyó en 1920" (fue en 1958) |
| Confusión de hechos | Mezcla hechos distintos | Atribuir el logro de una persona a otra |
| Invención de citas | Cita artículos o libros inexistentes | "Según Smith et al. (2023), 'AI Ethics Review'…" (ese artículo no existe) |
| Autocontradicción | Se contradice en su propia respuesta | "A tiene tres elementos: X, Y, Z, W" (dice tres y enumera cuatro) |
La más peligrosa: las citas inventadas
De los cuatro tipos, la invención de citas es la más peligrosa:
- Genera nombres de autores, años y títulos verosímiles
- Puede llegar a generar DOIs y URLs de apariencia real
- Sin verificación, es indistinguible de una cita auténtica
Si copias una en un informe o una propuesta, la inexistencia de la fuente puede descubrirse después y dañar gravemente tu credibilidad. Confirma siempre que toda cita existe realmente.
Cuatro mitigaciones
| Mitigación | Descripción |
|---|---|
| 1. Usar RAG | Buscar y consultar conocimiento externo; las respuestas pueden citar fuentes |
| 2. Preguntar con concreción | Evitar preguntas vagas; ser claro y específico |
| 3. Chain of Thought | Indicar "piensa paso a paso" y hacer visible el razonamiento |
| 4. Hábito de verificación | No aceptar la salida sin más; verificar siempre |
De estas, RAG (generación aumentada por recuperación) — hacer que el modelo responda consultando documentos internos o material fiable — es especialmente eficaz en entornos corporativos porque permite respuestas con fuentes citadas. Los detalles están en Qué es RAG: los 4 pasos y las bases vectoriales.
Un prompt anti-alucinaciones
Solo con hacer explícito el manejo de la incertidumbre en las instrucciones, la resistencia mejora notablemente. Este es el ejemplo de nuestro material de curso:
Responde a la pregunta siguiente.
Instrucciones importantes:
- Si no estás seguro, empieza con "No estoy seguro, pero"
- Si no hay fuente, indica claramente "esto requiere verificación"
- Si no lo sabes, responde con honestidad "no lo sé"
- Si es una suposición, dilo explícitamente: "es una suposición"
Pregunta: {pregunta del usuario}
Cómo convivir con las alucinaciones
La alucinación es una propiedad, no un bug. El objetivo no es eliminarla sino convivir con ella adecuadamente. Tres prácticas importan:
- Verificar: comprobar siempre las fuentes primarias de la información importante; contrastar con varias fuentes; confirmar que cada cita existe
- Mantener el escepticismo: preguntarse siempre "¿será verdad?"; cuanto más segura suena la respuesta, más cautela merece; revisar especialmente cifras y fechas concretas
- Aprovechar las fortalezas: usar la IA donde la creatividad importa más que la exactitud — ideación, brainstorming, borradores y pulido de textos
Fortalezas y debilidades
| Fuerte (la alucinación apenas importa) | Débil (verificación obligatoria) |
|---|---|
| Ideación y brainstorming | Hechos, cifras y fechas concretas |
| Reescritura y corrección de textos | Citas de artículos y libros |
| Plantillas de código | Información reciente (posterior al corte) |
| Resumir y estructurar | Conocimiento legal o médico especializado |
"Cuanto más segura suena la respuesta, más hay que dudar": esa es la actitud básica para usar IA generativa en el trabajo. Plasmar este reparto de tareas en las normas internas permite que todo el equipo use la IA con seguridad. Para formar a tu equipo de forma práctica, consulta nuestra formación corporativa en agentes de IA.
Preguntas frecuentes
Q. ¿Qué es exactamente una alucinación de la IA? A. Es cuando un LLM genera información sin base factual pero que suena verosímil: citar artículos inexistentes o describir detalles ficticios con seguridad. Lo crucial es que no se trata de un bug sino de una propiedad estructural: los LLM generan texto según lo que suena natural, no según lo que es correcto, por lo que ni siquiera los mejores modelos la eliminan por completo.
Q. ¿Por qué alucinan los LLM? A. Por cuatro causas principales. Primera: los LLM generan a partir de patrones estadísticos — qué palabra suele seguir a cuál — optimizando la naturalidad, no la verdad. Segunda: los datos de entrenamiento contienen desinformación y terminan en un corte de conocimiento. Tercera: los modelos siguen tendiendo a producir alguna respuesta antes que decir "no lo sé", pese a las mejoras de técnicas como RLHF. Cuarta: las métricas de evaluación suelen premiar respuestas detalladas y concretas aunque sean inciertas.
Q. ¿Qué tipo de alucinación es el más peligroso? A. La invención de citas. El modelo genera nombres de autores, años, títulos y a veces hasta DOIs y URLs verosímiles de artículos que no existen, indistinguibles de citas reales sin verificación. Si se copian en un informe, la fuente inexistente puede descubrirse más tarde y dañar tu credibilidad. Establece como norma confirmar la existencia de toda cita antes de usarla.
Q. ¿Cómo podemos reducir las alucinaciones? A. Funcionan bien cuatro mitigaciones: (1) usar RAG para que el modelo busque y cite conocimiento externo, (2) hacer preguntas concretas en lugar de vagas, (3) pedir "piensa paso a paso" para hacer visible el razonamiento (Chain of Thought) y (4) crear el hábito de verificar la salida. Además, añadir instrucciones explícitas como "antepón 'no estoy seguro' a las respuestas inciertas" y "di 'no lo sé' cuando no lo sepas" mejora la resistencia de forma medible.
Q. Si existen las alucinaciones, ¿es peligroso usar IA en el trabajo? A. No, si repartes bien el trabajo. La IA destaca en tareas donde la creatividad importa más que la exactitud: ideación, brainstorming, borradores, reescritura, resúmenes, plantillas de código. Para hechos concretos, cifras, fechas, citas, información reciente y juicios legales o médicos especializados, la verificación humana debe ser obligatoria. "Usar la IA en sus fortalezas y verificar en sus debilidades" es el modelo operativo básico.
Artículos relacionados
- Qué es RAG: los 4 pasos, bases de datos vectoriales y usos
- Tokens y ventana de contexto: guía de costes de LLM
- Skills, SubAgents y Agent Teams
- Prompt Injection y seguridad de LLM
- Formación corporativa en agentes de IA (práctica)
Servicios relacionados
¿Listo para poner a trabajar los agentes de IA?
Convierte lo que acabas de leer en flujos de trabajo reales. AI Agent Camp ayuda a profesionales no técnicos a pasar de usar a construir.
Última revisión: 2026-06-10