"ChatGPT no puede responder preguntas sobre nuestras políticas internas." "Necesitamos que la IA fundamente sus respuestas en información actualizada y en nuestros propios documentos." Toda organización que intenta llevar la IA generativa al trabajo real se topa con este problema, y la respuesta es RAG.
En esta guía explicamos cómo funciona RAG (Retrieval-Augmented Generation, generación aumentada por recuperación) en cuatro pasos, repasamos su motor — la base de datos vectorial —, las variantes avanzadas y cómo elegir entre RAG y fine-tuning. El contenido se basa en las lecciones fundamentales que usamos en nuestra formación corporativa y cursos online.
Qué aprenderás en este artículo
- Qué es RAG y por qué es necesario (los 4 problemas de un LLM sin RAG)
- Los 4 pasos: Ingestion → Retrieval → Augmentation → Generation
- Bases de datos vectoriales: búsqueda por palabra clave vs. búsqueda semántica
- Comparativa de 6 bases de datos vectoriales y recomendación para empezar
- Variantes avanzadas: Agentic RAG, Hybrid RAG, Graph RAG, Multimodal RAG
- RAG vs. fine-tuning: criterios claros de decisión
- Casos de negocio donde RAG aporta más valor
Qué es RAG: un examen con el libro abierto
RAG (Retrieval-Augmented Generation) es una técnica que amplía la generación de un LLM con información obtenida mediante búsqueda (retrieval). El concepto se propuso de forma sistemática por primera vez en el artículo "Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks" (Lewis et al., 2020).
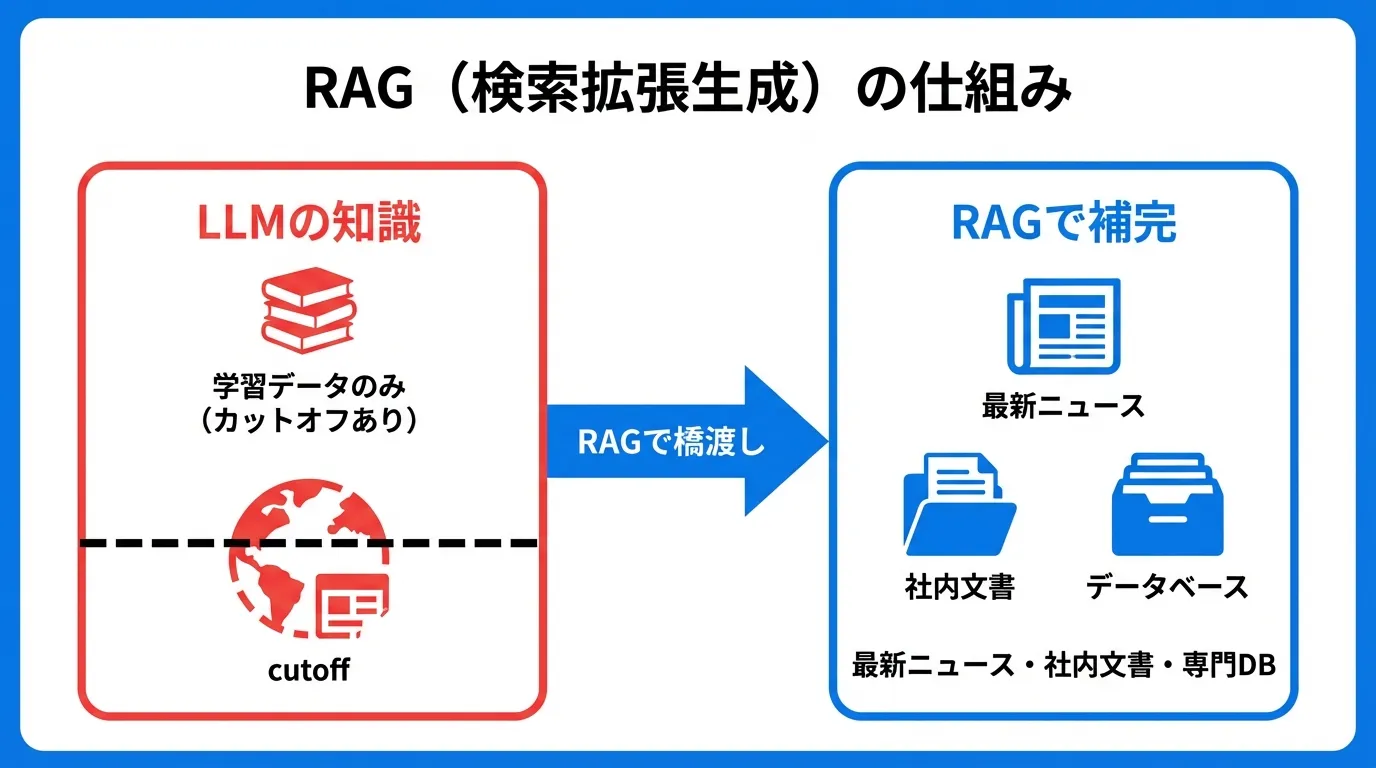
La mejor analogía es un examen con el libro abierto. Un LLM normal responde solo con el conocimiento memorizado, pero con RAG puede buscar en una base de datos los materiales relacionados con la pregunta y responder consultándolos. Por eso puede contestar con precisión sobre información reciente o documentos internos que el modelo nunca aprendió.
Los 4 problemas de un LLM sin RAG
| Problema | Descripción |
|---|---|
| Corte de conocimiento | No sabe nada posterior a sus datos de entrenamiento |
| Alucinaciones | Inventa lo que no sabe |
| Información privada | Los documentos internos nunca formaron parte del entrenamiento |
| Difícil de actualizar | Añadir conocimiento nuevo exige reentrenar |
RAG resuelve los cuatro a la inversa: la información actualizada llega con solo refrescar la base de datos, las respuestas incluyen fuentes y ganan precisión, los documentos internos pasan a ser consultables y resulta mucho más económico que reentrenar el modelo. Sobre las causas estructurales de las alucinaciones y cómo mitigarlas, consulta Alucinaciones de la IA: causas y soluciones.
Los 4 pasos de RAG
RAG opera en cuatro grandes pasos:
- Ingestion (ingesta) — la fase de preparación: cargar los documentos y convertirlos en vectores almacenados en una base de datos vectorial
- Retrieval (búsqueda) — recuperar la información relevante para la pregunta del usuario
- Augmentation (ampliación) — incorporar los resultados de la búsqueda al prompt
- Generation (generación) — el LLM produce la respuesta a partir del prompt ampliado
El punto clave: el LLM en sí no se modifica nunca. Solo cambia la información que se le entrega (el contexto). Así, el conocimiento propio de tu organización se vuelve utilizable sin ningún reentrenamiento. Para ver el panorama completo de qué entra en el contexto, lee Tokens y ventana de contexto.
Bases de datos vectoriales: el corazón de RAG
El motor central de RAG es la base de datos vectorial (Vector DB).
Una base de datos convencional busca por palabras clave exactas: nombre del autor, fecha de publicación, etc. Una base vectorial, en cambio, busca por proximidad de significado. Si buscas "divertido", también encuentra "alegre" o "feliz". Esto es la búsqueda semántica.
| Aspecto | Búsqueda por palabra clave | Búsqueda semántica |
|---|---|---|
| Coincidencia | Solo coincidencias exactas | También palabras de significado cercano |
| Ejemplo | "perro" → solo documentos con "perro" | "perro" → también documentos semánticamente relacionados |
| Mecanismo | Coincidencia de cadenas | Distancia en el espacio vectorial (los significados cercanos quedan próximos) |
Comparativa de las principales bases vectoriales
| Base de datos | Características | Uso recomendado |
|---|---|---|
| Pinecone | Totalmente gestionada, rápida, escalable | Producción, datos a gran escala |
| Chroma | Ligera, ejecutable en local, afín a Python | Desarrollo y prototipos |
| Weaviate | Soporte GraphQL, búsqueda híbrida | Consultas complejas |
| Milvus | Código abierto, alto rendimiento | Grandes despliegues on-premises |
| Qdrant | Escrita en Rust, filtrado rápido, APIs ricas | Búsqueda de alto rendimiento con filtros |
| pgvector | Extensión de PostgreSQL, operable con SQL | Añadir a un PostgreSQL existente |
Para empezar, lo recomendable es Chroma: fácil de probar en local y utilizable desde Python de inmediato. Al pasar a producción, considera Pinecone o pgvector.
Variantes avanzadas de RAG
Una vez dominada la base, conviene conocer cuatro extensiones:
| Variante | Resumen | Punto fuerte |
|---|---|---|
| Agentic RAG | Un agente de IA planifica y ejecuta la búsqueda, realiza varias consultas de forma autónoma y evalúa los resultados | Preguntas complejas |
| Hybrid RAG | Combina búsqueda vectorial y por palabra clave | Fuerte con nombres propios; mejor equilibrio precisión-cobertura |
| Graph RAG | Se combina con un grafo de conocimiento y aprovecha las relaciones entre entidades | Fuerte en "¿qué relación hay entre A y B?"; razonamiento complejo |
| Multimodal RAG | Indexa imágenes y vídeo además de texto | "¿Qué productos se parecen a esta imagen?"; tablas y figuras dentro de documentos |
Un camino realista: pon en marcha primero el RAG básico de 4 pasos; si la búsqueda de nombres propios falla, adopta Hybrid; si abundan las preguntas de relaciones, considera Graph.
RAG vs. fine-tuning: cómo elegir
Ambos personalizan un LLM, pero con fines distintos. El fine-tuning consiste en entrenar adicionalmente un modelo existente para una tarea o un estilo concretos.
| Aspecto | RAG | Fine-tuning |
|---|---|---|
| Propósito | Consultar conocimiento externo | Cambiar el comportamiento del modelo |
| Facilidad de actualización | Excelente: basta actualizar la BD | Limitada: requiere reentrenar |
| Coste | Bajo | Antes alto; técnicas como LoRA/QLoRA lo han reducido mucho |
| Latencia | Añade el paso de búsqueda | Sin procesamiento extra |
| Citación de fuentes | Posible | Difícil |
| Uso idóneo | FAQs, búsqueda documental, información reciente | Cambio de tono, especialización de dominio |
Los criterios de decisión son simples:
- Necesitas consultar información reciente o documentos internos → RAG
- Necesitas citar fuentes → RAG
- Quieres cambiar cómo habla o escribe la IA → fine-tuning
- Necesitas ambas cosas → combínalas (modelo fine-tuned + RAG)
Dónde aporta más valor RAG en el negocio
- Q&A sobre documentación interna — políticas, manuales, casos anteriores
- Respuestas que exigen información actual — cualquier dato posterior al corte de entrenamiento
- Respuestas auditables con fuentes — "esta respuesta se basa en la política X"
- Datos que cambian con frecuencia — información de producto, tarifas, FAQs
El patrón de despliegue probado: empieza en pequeño con un solo tipo de documento (por ejemplo, una FAQ interna), valida la calidad de las respuestas y la exactitud de las fuentes, y amplía después la cobertura. Para formar a todo tu equipo de forma práctica, consulta nuestra formación corporativa en agentes de IA.
Preguntas frecuentes
Q. ¿Qué es RAG en una frase? A. RAG (Retrieval-Augmented Generation, generación aumentada por recuperación) es una técnica que busca en una base de datos externa la información relevante para una pregunta y la utiliza para ampliar la generación de la respuesta del LLM. Funciona como un examen con el libro abierto: el modelo responde consultando material de referencia, por lo que puede contestar con precisión incluso sobre información reciente o documentos internos que nunca aprendió.
Q. ¿Por qué un chatbot normal no puede responder sobre nuestros documentos internos? A. Porque el conocimiento de un LLM se limita a sus datos de entrenamiento (corte de conocimiento). La información privada, como políticas internas o datos de clientes, nunca formó parte del entrenamiento, y ante temas desconocidos el modelo corre el riesgo de inventar respuestas (alucinación). Con RAG, tus documentos se ingieren en una base vectorial y en cada pregunta se recuperan los pasajes relevantes, de modo que la IA responde desde tu propia base de conocimiento sin reentrenar.
Q. ¿En qué se diferencia una base de datos vectorial de una convencional? A. En el mecanismo de búsqueda. Una base convencional encuentra coincidencias exactas de palabras clave, mientras que una vectorial convierte el texto en vectores numéricos y busca por proximidad de significado (búsqueda semántica). Buscar "divertido" también recupera documentos con "alegre". Como encuentra contenido relacionado aunque la pregunta use palabras distintas a las del documento, es esencial para el paso de búsqueda de RAG.
Q. ¿Deberíamos usar RAG o fine-tuning? A. Decide según el propósito. Si necesitas consultar información reciente o documentos internos, o citar fuentes, elige RAG: las actualizaciones solo requieren refrescar la base de datos y el coste es bajo. Si quieres cambiar el tono, el estilo o el comportamiento especializado de la IA, elige fine-tuning. Si necesitas ambas cosas, combinar un modelo fine-tuned con RAG es una arquitectura válida.
Q. ¿Cuál es la forma más pequeña y sensata de empezar? A. Usa una base vectorial ligera y orientada a prototipos como Chroma, limita el alcance a un tipo de documento (una FAQ interna, por ejemplo) y haz funcionar el pipeline de 4 pasos de principio a fin. Haz que las respuestas muestren sus fuentes y verifica que se consultan los documentos correctos antes de ampliar. Considera opciones preparadas para escalar, como Pinecone o pgvector, cuando pases a producción.
Artículos relacionados
- Alucinaciones de la IA: causas, tipos y soluciones
- Tokens y ventana de contexto: guía de costes de LLM
- Skills, SubAgents y Agent Teams
- Prompt Injection y seguridad de LLM
- Formación corporativa en agentes de IA (práctica)
Servicios relacionados
¿Listo para poner a trabajar los agentes de IA?
Convierte lo que acabas de leer en flujos de trabajo reales. AI Agent Camp ayuda a profesionales no técnicos a pasar de usar a construir.
Última revisión: 2026-06-10