"¿Por qué la factura de la IA es así?" "La IA olvida mis instrucciones iniciales cuando la conversación se alarga." Ambos misterios tienen la misma explicación: los tokens y la ventana de contexto.
En esta guía explicamos los dos conceptos que determinan la capacidad y el coste de un LLM, y repasamos técnicas prácticas para reducir costes sin perder calidad de salida. El contenido se basa en las lecciones fundamentales que usamos en nuestra formación corporativa y cursos online.
Qué aprenderás en este artículo
- Qué es un token: la unidad mínima que procesa un LLM
- Por qué es necesaria la tokenización: del texto a los IDs numéricos
- Reglas para estimar tokens y por qué algunos idiomas salen "más caros"
- Tokens de entrada vs. de salida: cómo funciona el precio, con ejemplo
- Qué es la ventana de contexto: comparativa de los principales modelos
- Por qué la IA "olvida" instrucciones: el contenido del contexto y la compactación
- Seis técnicas para optimizar el uso de tokens y una lista de autocomprobación
Qué es un token: la unidad mínima de un LLM
Un token es la unidad mínima que utiliza un LLM (modelo de lenguaje de gran tamaño) para procesar texto. El modelo divide el texto en fragmentos de palabras o caracteres antes de procesarlo.
- En inglés: "Hello, world!" → ["Hello", ",", " world", "!"] (unos 4 tokens)
- En japonés, un saludo de cinco caracteres puede dividirse en 3 tokens (varía según el modelo)
Tres puntos clave:
- Los idiomas difieren en eficiencia de tokens: el japonés, por ejemplo, consume más tokens que el inglés para el mismo significado
- Un token ≈ unos 4 caracteres en inglés (1–2 caracteres en japonés)
- El código y los símbolos siguen sus propias reglas de tokenización
Por qué es necesaria la tokenización
Los ordenadores no entienden los caracteres directamente; el texto debe convertirse en números:
- Texto: "Hello AI"
- Tokenización: ["Hello", " AI"]
- Conversión a IDs: [15496, 9552]
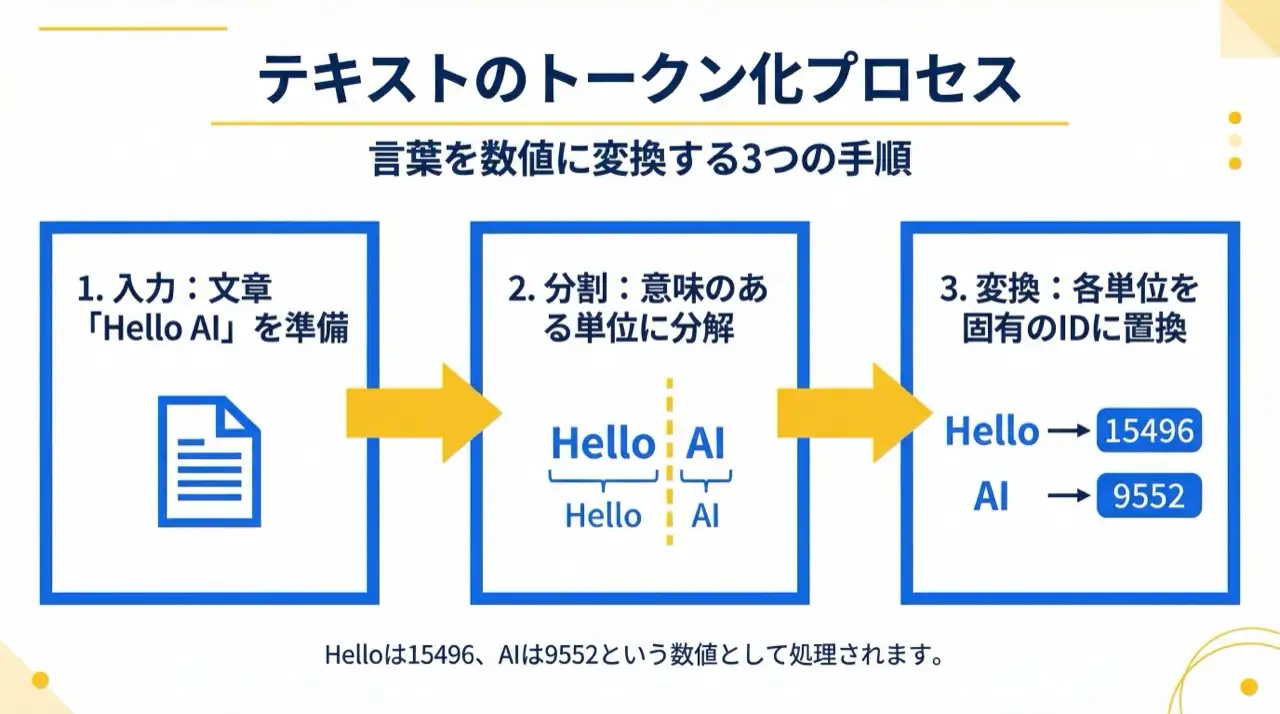
Cada token recibe un ID numérico único, y esos IDs son la entrada del modelo. Es decir, un LLM aprende patrones de IDs de tokens, no "el significado de las palabras".
Reglas aproximadas de estimación
| Cantidad de texto | Tokens aproximados |
|---|---|
| 1.000 palabras en inglés | ~750 tokens |
| 1.000 caracteres en japonés | ~500–700 tokens |
| 100 líneas de código | ~500–1.500 tokens |
Comprobar el número de tokens antes de llamar a la API permite prever los costes.
Tokens de entrada vs. de salida: cómo funciona el precio
El uso de un LLM se factura como tokens de entrada más tokens de salida, con tarifas distintas.
| Categoría | Qué incluye | Nivel de precio |
|---|---|---|
| Tokens de entrada | Tu prompt, el system prompt, el historial de conversación, archivos adjuntos | Relativamente barato |
| Tokens de salida | El texto de respuesta de la IA, el código generado, la respuesta completa | Más caro que la entrada (2–8 veces) |
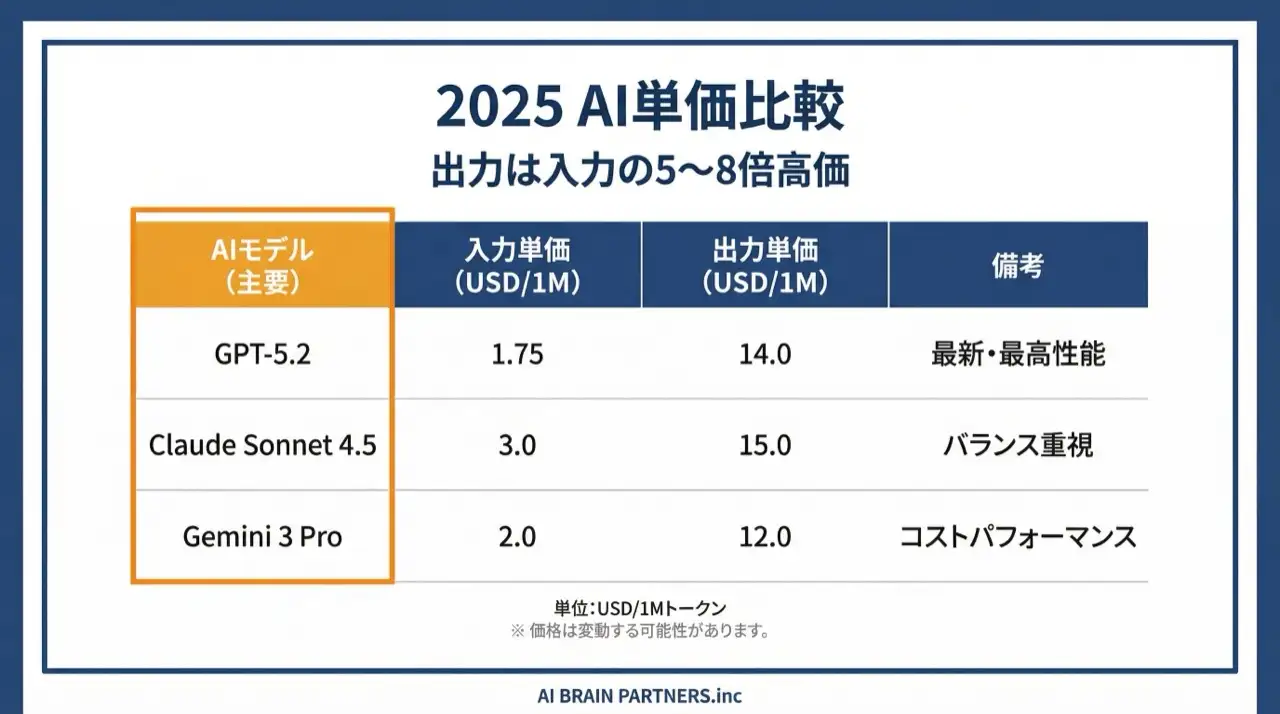
Ejemplo de cálculo de nuestro curso (GPT-5.2, 2026):
- Entrada: 1.000 tokens × 1,75 $/1M = 0,00175 $
- Salida: 500 tokens × 14 $/1M = 0,007 $
- Total: unos 0,009 $ por petición
Poco por petición, pero cientos de peticiones diarias en un equipo suman rápido. Por eso especificar el formato de salida para limitar los tokens de salida es la técnica de ahorro más eficaz.
Qué es la ventana de contexto
La ventana de contexto es el número máximo de tokens que un LLM puede procesar a la vez. Comparativa de los principales modelos (material del curso, 2026):
| Modelo | Ventana de contexto | Equivalencia aproximada |
|---|---|---|
| GPT-5.2 | 400K tokens | ~3 novelas |
| Claude Sonnet 4.6 | 200K tokens (1M Beta) | ~1,5 novelas |
| Gemini 3 Pro | 1M tokens | ~7 novelas |
| Llama 4 Scout | 10M tokens | ~70 novelas |
| DeepSeek-V3.2 | 128K tokens | ~1 novela |
Por qué importa:
- Es el límite duro al procesar conversaciones largas o archivos grandes
- Más allá de la ventana, la información antigua se "olvida"
- Ventana más grande = más información manejada a la vez
Por qué la IA "olvida" instrucciones: qué hay dentro del contexto
"Di instrucciones claras, pero a mitad de camino la IA empezó a ignorarlas." El culpable es la ventana de contexto.
La premisa crucial: la IA no "recuerda" la conversación. En cada turno, la ventana de contexto se llena con todo lo siguiente:
- System prompt: la configuración y el comportamiento base de la IA
- Prompt del usuario: la pregunta o instrucción actual
- Tools / MCP / Rules: herramientas disponibles, conexiones externas, reglas del proyecto
- Documentos (RAG): material de referencia recuperado por búsqueda
- Historial de conversación: todo el chat hasta el momento
Si cierras la sesión, la IA lo olvida todo. Para memoria a largo plazo hay que guardar la información explícitamente con funciones de memoria o escribiéndola en archivos.
Compactación: qué pasa cuando la ventana se llena
Cuando la conversación se acerca al límite, se activa la compactación: los mensajes antiguos se resumen y se eliminan. Se libera espacio, pero se pierde información. La mayoría de los casos de "la IA olvidó mis instrucciones iniciales" se explican así.
Para hacerse una idea de la escala: leer una vez un archivo de 1.000 líneas consume unos 4.000 tokens. Leer 30 archivos y ejecutar 20 comandos puede superar los 100.000 tokens; los trabajos grandes no funcionarían sin compactación.
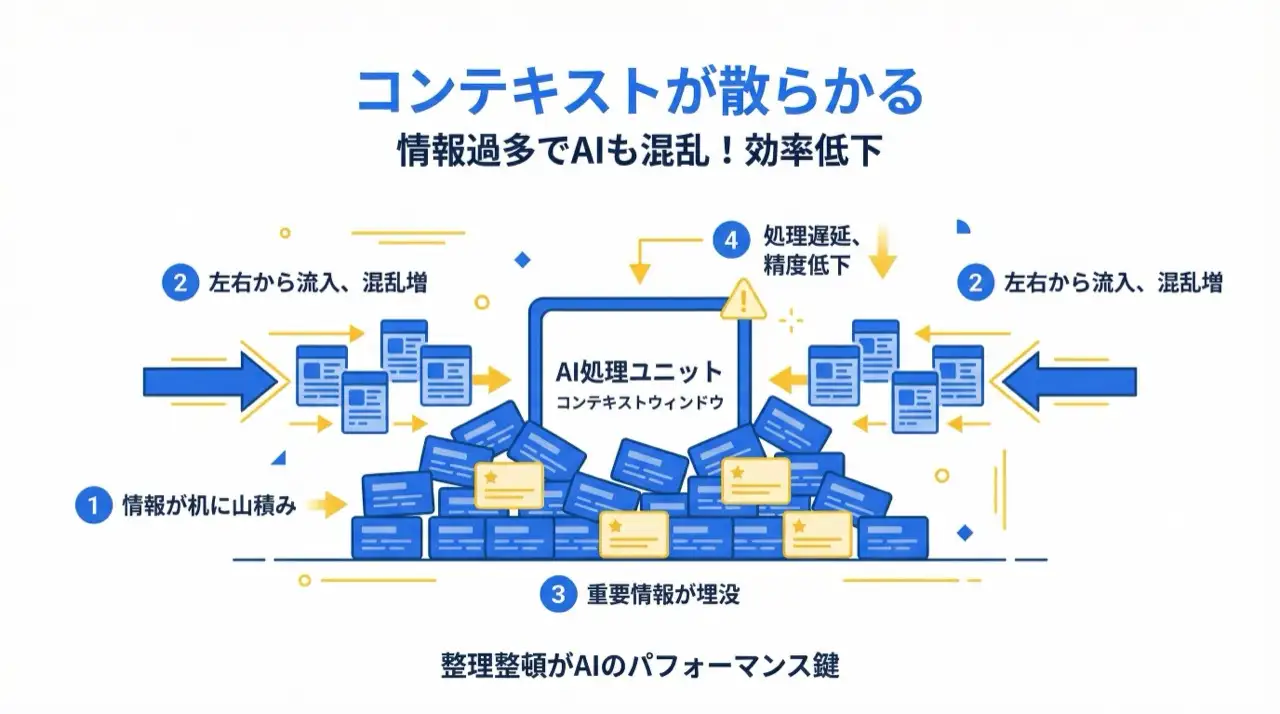
Cuando todo tipo de información se amontona en el contexto, la IA se confunde como una persona ante un escritorio desordenado. Mantener limpio el contexto es la forma más sencilla de conservar la calidad de salida. El remedio es simple: iniciar una sesión nueva por tarea y anotar las decisiones importantes en archivos.
Seis técnicas para optimizar el uso de tokens
| Técnica | Qué hacer | Ejemplo |
|---|---|---|
| 1. Prompts concisos | Eliminar relleno; centrar la instrucción en lo esencial | "Haz X, y si es posible…" → "Ejecuta X" |
| 2. Solo lo necesario | Extraer solo la parte relevante de archivos grandes | Pasar la función o sección concreta, no el archivo entero |
| 3. Especificar el formato de salida | Indicar el formato para evitar relleno | "JSON, solo claves", "lista de máximo 5 puntos" |
| 4. Gestionar el historial | Resumir y reiniciar conversaciones largas | Tras ~20 turnos, resumir lo clave y abrir un chat nuevo |
| 5. Elegir bien el modelo | Ajustar el modelo a la complejidad de la tarea | Modelos ligeros para tareas simples, potentes para las complejas |
| 6. Considerar el idioma | El inglés puede ser más eficiente en tokens | Instrucciones técnicas en inglés, resultado en tu idioma |
Autocomprobación cuando el coste parece alto
Los puntos de mayor impacto de la lista de nuestro curso:
- Una tarea = un chat: continuar tareas sin relación en una misma conversación acumula contexto irrelevante
- No adjuntar archivos enormes enteros: un archivo de más de 1.000 líneas consume por sí solo más de 4.000 tokens; pasa solo el rango necesario
- Planificar antes de ejecutar: el ensayo y error sin plan consume 2–3 veces más tokens por relecturas y repeticiones
- Vigilar el tamaño de los archivos de reglas: se cargan en el contexto en cada turno; depura las reglas obsoletas con regularidad
- Controlar el volumen de salida: "explícalo en detalle" infla los tokens de salida; especifica "conciso, en lista"
En resumen: consumo de tokens = entrada (contexto) + salida (respuesta). Mantén pequeña la entrada y controla el formato de salida, y el mismo trabajo costará muchísimo menos.
Preguntas frecuentes
Q. ¿Qué es un token y en qué se diferencia del número de caracteres? A. Un token es la unidad mínima con la que un LLM procesa texto, y no equivale uno a uno a los caracteres. En inglés, un token son unos 4 caracteres; 1.000 palabras en inglés equivalen a unos 750 tokens, mientras que 1.000 caracteres en japonés suponen entre 500 y 700 tokens. Los idiomas difieren en eficiencia de tokens — el mismo significado puede costar más tokens en un idioma que en otro —, lo cual afecta directamente a la gestión de costes.
Q. ¿Por qué la salida de la IA cuesta más que la entrada? A. Las tarifas de los LLM separan los tokens de entrada y de salida, y la salida suele costar entre 2 y 8 veces más. Por ejemplo, con GPT-5.2 (2026), una petición con 1.000 tokens de entrada y 500 de salida cuesta unos 0,009 $. Por eso, restringir el formato de salida — "lista de máximo 5 puntos" — es la optimización más barata y eficaz: recorta directamente la parte cara de la factura y además mejora la legibilidad.
Q. ¿Por qué la IA olvida mis instrucciones a mitad de conversación? A. Porque la IA no recuerda nada: en cada turno, todo el contexto (system prompt, reglas, documentos de referencia, historial completo) se empaqueta en la ventana de contexto. Cuando la conversación se acerca al límite, la compactación resume y elimina los mensajes antiguos, perdiendo información. Las contramedidas: una tarea por chat, resumir y reiniciar las conversaciones largas, y anotar las decisiones importantes en archivos en lugar de confiar en la "memoria" de la IA.
Q. ¿Una ventana de contexto más grande siempre es mejor? A. Una ventana mayor maneja más información a la vez (GPT-5.2 ofrece 400K tokens, Gemini 3 Pro 1M, Llama 4 Scout 10M), pero no es una licencia para meterlo todo. La información irrelevante confunde al modelo y degrada la precisión, y más tokens de entrada significan más coste. En el uso diario, pasar solo la información necesaria y mantener el contexto limpio mejora la calidad de salida más que el tamaño bruto de la ventana.
Q. ¿Cuál es la reducción de coste más sencilla que puedo aplicar hoy? A. Especificar el formato de salida. Restricciones como "lista de máximo 5 puntos" o "JSON, solo claves" reducen directamente los costosos tokens de salida. Después: aplicar una tarea por chat y no pegar nunca archivos enormes enteros, sino solo el rango relevante. Las tres medidas no requieren cambiar configuraciones, funcionan de inmediato y no implican pérdida de calidad.
Artículos relacionados
- Qué es RAG: los 4 pasos, bases de datos vectoriales y usos
- Alucinaciones de la IA: causas, tipos y soluciones
- Skills, SubAgents y Agent Teams
- Terminal y CLI para principiantes
- Formación corporativa en agentes de IA (práctica)
Servicios relacionados
¿Listo para poner a trabajar los agentes de IA?
Convierte lo que acabas de leer en flujos de trabajo reales. AI Agent Camp ayuda a profesionales no técnicos a pasar de usar a construir.
Última revisión: 2026-06-10