「生成AIとは結局なんなのか」「ChatGPTは触ったが、自社の業務にどう効くのか分からない」——非エンジニアの業務担当者ほど、ここで止まりがちです。
この記事では、生成AIを法人の業務自動化とAIエージェント活用の視点から整理します。一般的な「生成AIとは」の解説と違い、仕組み(LLM・トークン・ハルシネーション)を業務判断に必要な深さまで押さえたうえで、最後は「どう自分の業務に落とすか」まで一気通貫でつなげます。内容は、当スクールが法人研修・オンラインコースで実際に使っている基礎講義(Foundation)をベースにしています。
生成AIの仕組みやエージェント化の全体像をさらに深く知りたい方は、英語版の体系ガイド The Complete Guide to AI Agents for Business も参照してください。
この記事でわかること
- 生成AIとは何か(一言でいうと)
- AIの進化と現在地 — なぜ今「生成AI」なのか
- 生成AIの仕組み — LLMは「次の単語」を予測している
- トークンとコスト — 業務利用で知っておくべき単位
- 従来のAI・チャットボットとの違いと、業務でできること
- ハルシネーション — 生成AI最大の注意点と対策
- 生成AI → AIエージェントへの進化と、AI自律性の6段階
- RAGで社内ナレッジとつなぐ方法と、業務に落とす導入ステップ
生成AIとは — 一言でいうと
生成AI(Generative AI)とは、テキスト・画像・コード・音声などを「新しく生成」できるAIのことです。膨大なデータで学習した大規模言語モデル(LLM)が中心で、ChatGPT・Claude・Gemini などが代表例です。
ポイントは「検索して既存の答えを返す」のではなく、文脈をふまえてその場で文章や成果物を作り出す点にあります。
そして本質はとてもシンプルです。LLMは「テキストを入力すると、テキストが出力される」装置です。この単純な仕組みに、後述する「ツール」と「自律実行のループ」が加わることで、業務を任せられるAIエージェントへと進化します。
AIの進化と現在地 — なぜ今「生成AI」なのか
「AIは昔からあったのでは?」という疑問はもっともです。AIは段階的に進化し、2020年代に生成AIの時代へ入りました。
| 年代 | 段階 | 何ができたか |
|---|---|---|
| 1950年代〜 | ルールベースAI | if-thenルールやエキスパートシステム。決められた条件分岐のみ |
| 1980年代〜 | 機械学習 | レコメンドエンジン、指紋認証などのパターンマッチング |
| 2010年代〜 | 深層学習 | 画像分類、手書き文字認識。「猫」などの概念を自動発見 |
| 2020年代〜 | 生成AI / LLM | Transformerの登場により、文章・コード・画像を「生成」できるように |
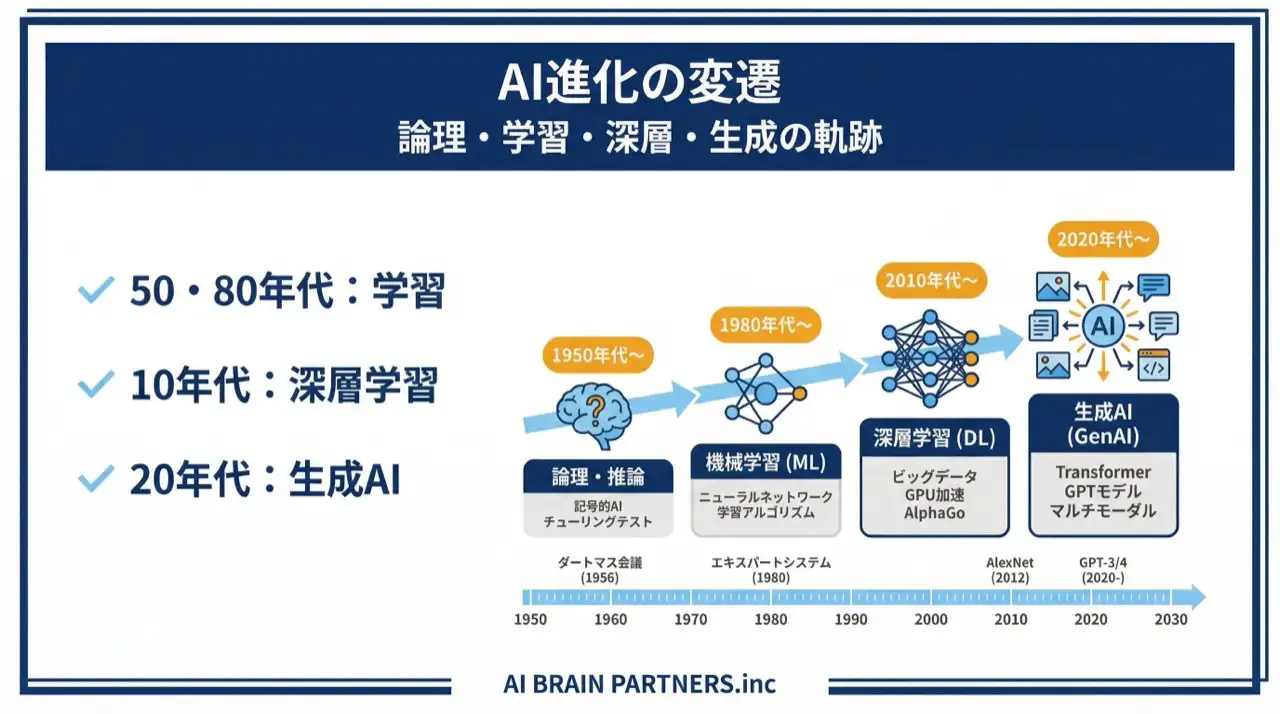
転機は2017年の論文「Attention Is All You Need」で発表されたTransformerというアーキテクチャです。従来のモデルが単語を1つずつ順番に処理していたのに対し、Transformerは文章全体を一度に並列処理できるため、高速で長文にも強い。これが2022年のChatGPT登場につながり、生成AIが一般に普及しました。
なお、用語の関係は「AI ⊃ 機械学習 ⊃ 深層学習 ⊃ LLM」という包含関係で覚えておくと、ベンダーの説明資料を読むときに混乱しません。
生成AIの仕組み — LLMは「次の単語」を予測している
生成AIの賢さの正体は、**Next Token Prediction(次トークン予測)**という仕組みです。
LLMはテキストを「トークン」という小さな単位に分割して処理し、「次に来る確率が最も高いトークン」を予測してつなげることで文章を生成します。
たとえば「今日の天気は」という入力に対して、モデル内部では次のような確率計算が行われます。
- 「晴れ」 40%
- 「曇り」 25%
- 「雨」 20%
- 「良い」 10%
- その他 5%
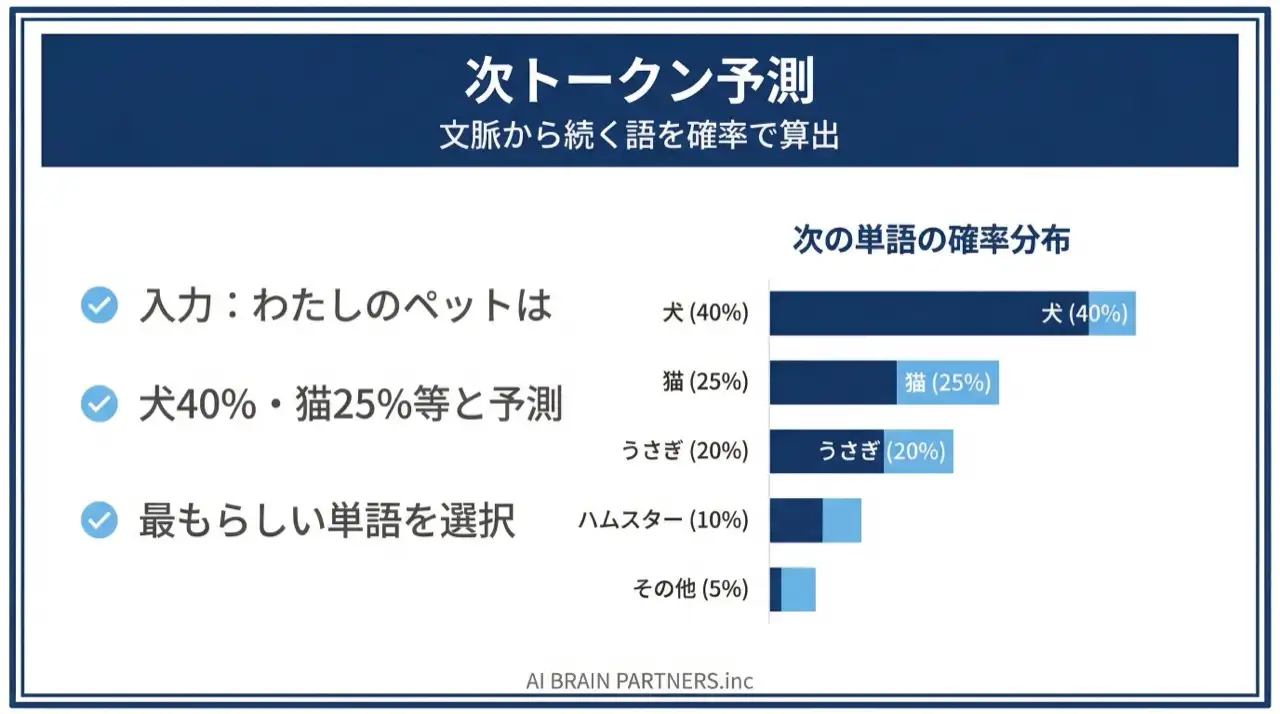
この予測を1トークンずつ繰り返す(自己回帰生成)ことで、自然な文章ができあがります。
業務視点で重要な示唆は2つあります。
- LLMは「正しさ」ではなく「自然さ」を基準に生成している — だから後述のハルシネーション(もっともらしい誤り)が構造的に起こります
- 出力にはランダム性がある — Temperature というパラメータで制御でき、低くすれば要約・抽出など再現性重視のタスクに、高くすればブレストやコピーライティングなど発想重視のタスクに向きます
トークンとコスト — 業務利用で知っておくべき単位
生成AIを業務で本格利用するなら、トークンという単位の感覚を持っておくと、コスト管理とツール選定で失敗しません。
- トークンはLLMがテキストを処理する最小単位。日本語1,000文字 ≒ 500〜700トークンが目安
- 日本語は英語よりトークン効率が悪く、同じ意味でも多くのトークンを消費します
- 料金は「入力トークン+出力トークン」の合計で決まり、出力は入力の2〜8倍高価な料金設定が一般的です
また、LLMにはコンテキストウィンドウ(一度に処理できるトークン数の上限)があります。長い会話や大きな資料を扱うと上限に達し、古い情報が「忘れられた」ような挙動になります。「AIが指示を忘れる」と感じる現象の多くは、この仕組みによるものです。
コストを抑える基本は次の3つです。
- プロンプトを簡潔に — 冗長な前置きを削る
- 必要な情報だけ渡す — 資料全体ではなく該当箇所のみ
- 出力形式を指定する — 「箇条書き5項目以内で」のように指定すると出力トークンを抑えられる
従来のAI・チャットボットとの違い
| 観点 | 従来のチャットボット | 生成AI |
|---|---|---|
| 応答 | 決められた回答を返す | 文脈に応じて生成する |
| 対応範囲 | 想定済みの質問のみ | 未知の依頼にも対応 |
| 出力 | 定型テキスト | 文章・要約・コード・画像 |
| 仕組み | if-thenルール | 次トークン予測(LLM) |
| 業務での価値 | FAQ自動応答 | 資料作成・分析・下書きまで |
生成AIで「業務」としてできること
- 議事録・日報・レポートの要約と下書き
- メール・提案文・SNS投稿の作成
- 表計算データの整理・分類・集計の補助
- 社内ドキュメントへの質問応答(ナレッジ検索)
- コード生成・データ処理の自動化
ただし、ここまでは多くが「人が指示するたびに1回だけ動く」使い方です。本当の業務自動化は、後述の「AIエージェント」で実現します。
ハルシネーション — 生成AI最大の注意点
業務利用の前に必ず押さえるべきなのがハルシネーション(AIが事実に基づかない情報をもっともらしく生成する現象)です。これは不具合ではなく、「次に自然なトークンを予測する」というLLMの構造的な特性です。
代表的なパターンは4つあります。
| 種類 | 内容 | 例 |
|---|---|---|
| 事実の捏造 | 存在しない事実を作り出す | 実在しない統計値・日付を提示 |
| 事実の混同 | 別の事実を混ぜてしまう | 人物Aの実績を人物Bのものとして説明 |
| 引用の捏造 | 存在しない論文・記事を引用 | もっともらしい著者名・URLまで生成 |
| 自己矛盾 | 回答内で矛盾する | 「3つあります」と言いながら4つ挙げる |
特に危険なのが引用の捏造で、検証しないと本物と区別がつきません。業務での対策は次の通りです。
- 重要な数値・日付・固有名詞は原典を確認する運用ルールにする
- **「不確かな場合は『わかりません』と答えて」**と指示に明記する
- RAG(後述)で社内文書を参照させ、出典付きで回答させる
- 得意分野(アイデア出し・下書き・要約)と苦手分野(事実確認・最新情報・専門的な法務/医療判断)を分けて使う
「自信満々な回答ほど疑う」——これが生成AIを業務で使う側の基本姿勢です。
生成AI → AIエージェントへ(自律実行)
AIエージェントとは、生成AIに「目標」を渡すと、自分で計画→ツール実行→結果確認→再計画を繰り返して、複数ステップの業務を最後までやり切るソフトウェアです。
- チャットボット = 1問1答
- AIエージェント = 「やっておいて」で複数工程を完了
ここで鍵になるのが**ツール(Tool Use)です。LLM単体は「テキスト生成」しかできず、今日の日付すら知りません。ファイルの読み書き・コマンド実行・Web検索・外部サービス連携(Slack・カレンダー・データベースなど)といったツールと接続されてはじめて、現実の業務に「手を出せる」ようになります。さらにMCP(Model Context Protocol)**という標準規格の普及で、外部サービスとの接続が以前よりはるかに簡単になりました。
エージェントの動作は「計画 → 実行 → 観察 → 再計画」のループです。たとえば「毎朝の日報を作って関係者に共有」なら、メール確認→要約→下書き→送信までを、途中の結果を自分で確認しながら自律的にこなします。途中でエラーが出れば自己修正も試みます。
| 比較項目 | 従来のAIアシスタント | AIエージェント |
|---|---|---|
| 動作方式 | 質問に対して1回の応答 | 目標に向けて複数ステップを自律実行 |
| ツール使用 | 基本的になし | ファイル・コマンド・Web・外部APIを状況に応じて使用 |
| 計画能力 | 受動的(指示を待つ) | 能動的(自ら計画を立てる) |
| エラー対応 | ユーザーが修正指示 | 自己修正・リトライを試みる |
| 例 | ChatGPT(基本モード) | Claude Code、Cursor Agent、Devin |
業務別の具体例は 製造・工場のAIエージェント活用、DX部門での進め方、複数エージェントの連携設計 で詳しく解説しています。
AI自律性の6段階 — 自社の現在地を知る
「どこまでAIに任せるか」を判断する物差しとして、自律性をレベル0〜5の6段階で整理すると、社内の議論がかみ合いやすくなります。
| レベル | 名称 | 説明 | 例 |
|---|---|---|---|
| 0 | 人間のみの手動運用 | すべて人間が手動で実行 | 手作業のデータ入力・メール対応 |
| 1 | ルールベース自動化 | if-thenルールの単純な自動化 | Excelマクロ、メールフィルター、定型RPA |
| 2 | AI補助 | AIが判断を補助し、人間が確認・実行 | ChatGPTでの下書き、コード補完 |
| 3 | エージェント型ワークフロー | AIが計画・複数ステップ実行、人間が承認 | Claude Code / Cursor Agent(標準モード) |
| 4 | 半自律型エージェント | AIが大半を自律遂行、重要判断のみ人間 | 自動承認モードでのエージェント運用 |
| 5 | 完全自律型 | 人間の介入なしに完遂 | 研究段階 |
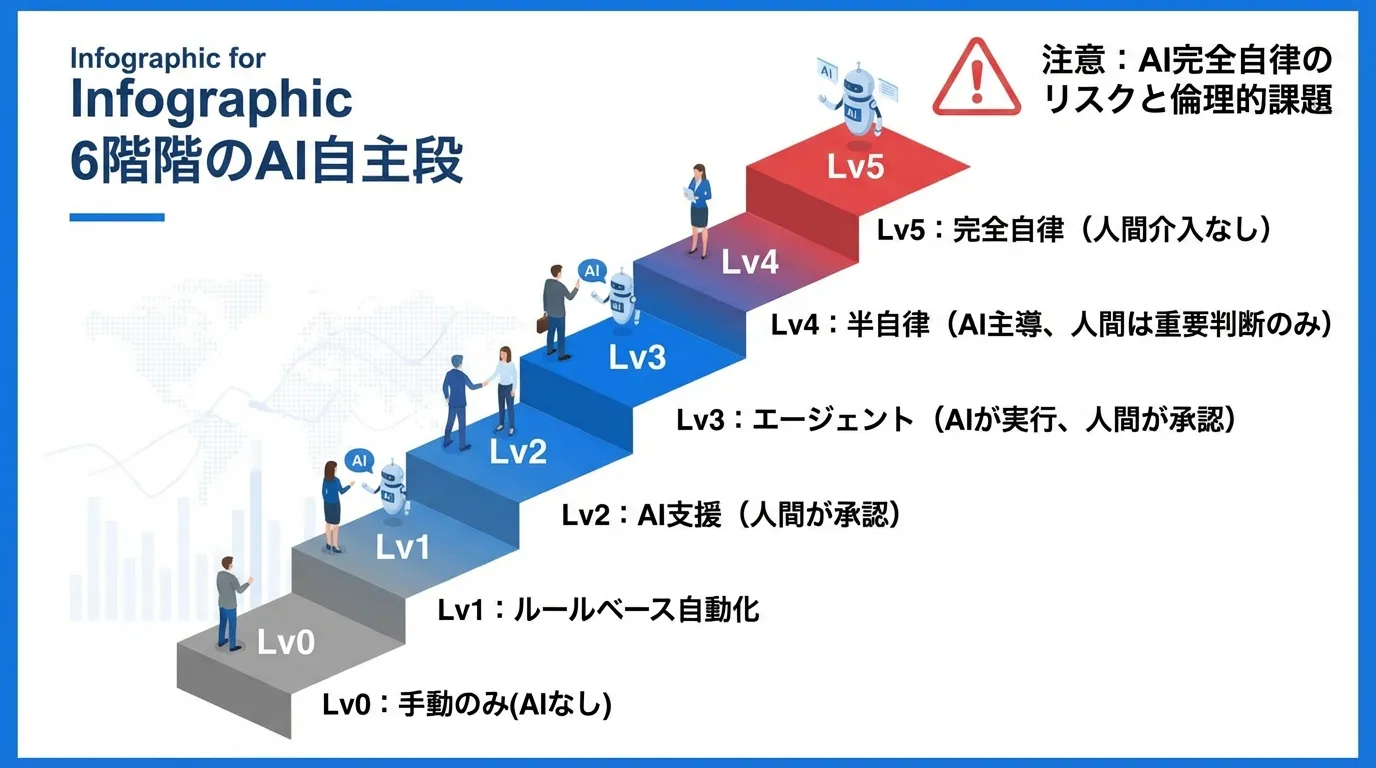
多くの企業の現在地は**レベル2(AI補助)**です。ChatGPTで下書きを作る段階から、レベル3〜4(エージェント型〜半自律型)へ進むには、後述するガードレール(権限・ルール・検証手順)の設計が必要になります。重要なのは「高い自律性 = 高いリスク」であり、タスクの重要度に応じて自律レベルを調整することです。
RAG — 社内ナレッジと生成AIをつなぐ
「自社の規程や過去事例をふまえて回答してほしい」という法人ニーズに応えるのが**RAG(Retrieval-Augmented Generation:検索拡張生成)**です。
RAGは「教科書持ち込み可の試験」にたとえられます。通常のLLMが暗記した知識だけで答えるのに対し、RAGでは質問に関連する社内文書をデータベースから検索し、それを見ながら回答します。
法人にとってのメリットは明確です。
- 最新情報に対応 — モデルを再学習せず、文書データベースの更新だけでよい
- 出典を明示できる — 「この回答は規程◯◯の第◯条に基づく」と示せるため、ハルシネーション対策になる
- 社内文書を活用 — LLMが学習していない自社固有の情報に答えられる
- コスト効率 — モデルのファインチューニング(追加学習)より安価
「社内FAQ・ドキュメント検索・最新情報の参照」はRAG、「AIの話し方やスタイル自体を変えたい」はファインチューニング、と使い分けるのが基本です。
法人で生成AIを業務に落とすステップ
- 1つの定型業務を選ぶ — 毎日・毎週くり返している、判断が軽い業務から
- 手順を言葉で書き出す — コードではなく自然言語で「やること」を整理
- 生成AI/エージェントに任せて検証 — 小さく試し、結果を見て指示を調整
- ガードレールを決めて運用 — 実データはマスキング、権限は最小限から。前述の自律性レベルを意識し、最初は「人間が承認する」レベル3で運用
- 検証方法をセットで渡す — 「やっておいて」ではなく「実行して、結果を確認して、確認結果も報告して」と指示すると品質が安定します
ツールのセットアップは Claude Code セットアップ完全ガイド を参考にしてください。社内チームでまとめて習得したい場合は 法人向けAIエージェント研修 でハンズオン形式の導入が可能です。
よくある質問
Q. 生成AIとAIエージェントは何が違いますか? A. 生成AIは指示するたびに文章や成果物を1回生成するツールで、AIエージェントはその生成AIを使って「目標達成まで複数ステップを自律実行」する仕組みです。エージェントはツール(ファイル操作・コマンド実行・外部サービス連携)を使い、計画→実行→観察→再計画のループを回します。日報作成のような複数工程の業務はエージェントが向いています。
Q. 生成AIはなぜ間違える(ハルシネーションする)のですか? A. LLMは「正しいか」ではなく「次に来る確率が高いトークン(単語)は何か」を基準に文章を生成しているためです。これは不具合ではなく構造的な特性です。重要な数値・引用は原典を確認する、不確かな場合は「わかりません」と答えるよう指示する、RAGで出典付き回答にする、といった対策を運用に組み込みます。
Q. 非エンジニアでも業務に使えますか? A. 使えます。ChatGPTやGeminiを日常的に触っている社会人であれば、プログラミング経験がなくても始められます。財務・人事・広報・営業など非エンジニア職での活用が広がっています。エージェント活用に必要なのはコードではなく「業務手順を言葉で明文化する力」です。
Q. 何から始めればよいですか? A. 毎日・毎週くり返していて判断の軽い定型業務を1つ選び、手順を自然言語で書き出して生成AIに任せてみるのが最短です。小さく試して指示を調整し、ガードレール(マスキング・最小権限・人間の承認)を決めてから広げます。自律性レベルでいえば、まずレベル3(人間が承認)からの運用が安全です。
Q. 社内データを使った回答は危なくないですか? A. RAGを使えば、社内文書を検索して出典付きで回答させられるため、ハルシネーションのリスクを抑えられます。あわせて、実データのマスキング・アクセス権限の最小化・重要操作の人間承認という3点をガードレールとして整備するのが法人導入の基本です。
関連記事
- プロンプトエンジニアリングとは?AIエージェント時代の実践入門
- 製造・工場のAIエージェント活用ガイド
- DX部門でのAIエージェントの進め方
- 複数AIエージェントの連携設計
- Claude Code セットアップ完全ガイド
- 法人向けAIエージェント研修(ハンズオン)
関連サービス
最終確認日: 2026-06-10