"The AI told me something wrong with total confidence." "It cited a paper that doesn't exist." Everyone who uses generative AI at work runs into this phenomenon sooner or later. It is called a hallucination.
This guide explains systematically why hallucinations happen (four causes), what patterns they take (four types), and how to mitigate them in practice. The content is based on the foundation lectures we use in our corporate training and online courses.
To understand the underlying mechanism (next-token prediction) first, start with The Complete Guide to AI Agents for Business.
What you will learn
- What a hallucination is — a structural property, not a bug
- Why hallucinations happen — the four causes
- The four types of hallucination, and why fabricated citations are the most dangerous
- Four mitigations, plus a concrete anti-hallucination prompt
- How to live with hallucinations — verify, question, and play to strengths
- Where AI is strong and where verification is mandatory
What is a hallucination? A plausible lie
A hallucination is a phenomenon in which an LLM (large language model) generates information that is not grounded in fact, yet sounds plausible. It may cite papers that do not exist or describe a fictional person's profile in detail.
One crucial premise: LLMs do not guarantee accuracy. Even the most capable model will sometimes state falsehoods with complete confidence. This is not a bug — it is a structural property of how LLMs work.
The human brain offers a useful analogy. We also fill memory gaps with "plausible-sounding" information: you confidently say a movie came out in 2015 when it was actually 2017. LLMs behave similarly. Asked about information they never learned or only vaguely encountered, they generate an answer that merely "sounds right."

Why hallucinations happen: four causes
| Cause | Description |
|---|---|
| 1. Statistical pattern matching | Whether LLMs "understand" in the human sense remains debated among researchers. Fundamentally they learn statistical patterns — which word tends to follow which — and generate based on what makes a natural-sounding sentence, not on what is correct |
| 2. Training data problems | Internet data contains misinformation, and the model knows nothing after its knowledge cutoff |
| 3. Weak expression of uncertainty | Early LLMs were poorly trained to express uncertainty. Techniques like RLHF (reinforcement learning from human feedback) have improved this, but models still tend to be optimized toward producing an answer rather than saying "I don't know" |
| 4. Evaluation metric problems | When "detailed answers" score well in evaluations, answering specifically — even when uncertain — tends to be rewarded, while "I don't know" can be penalized |
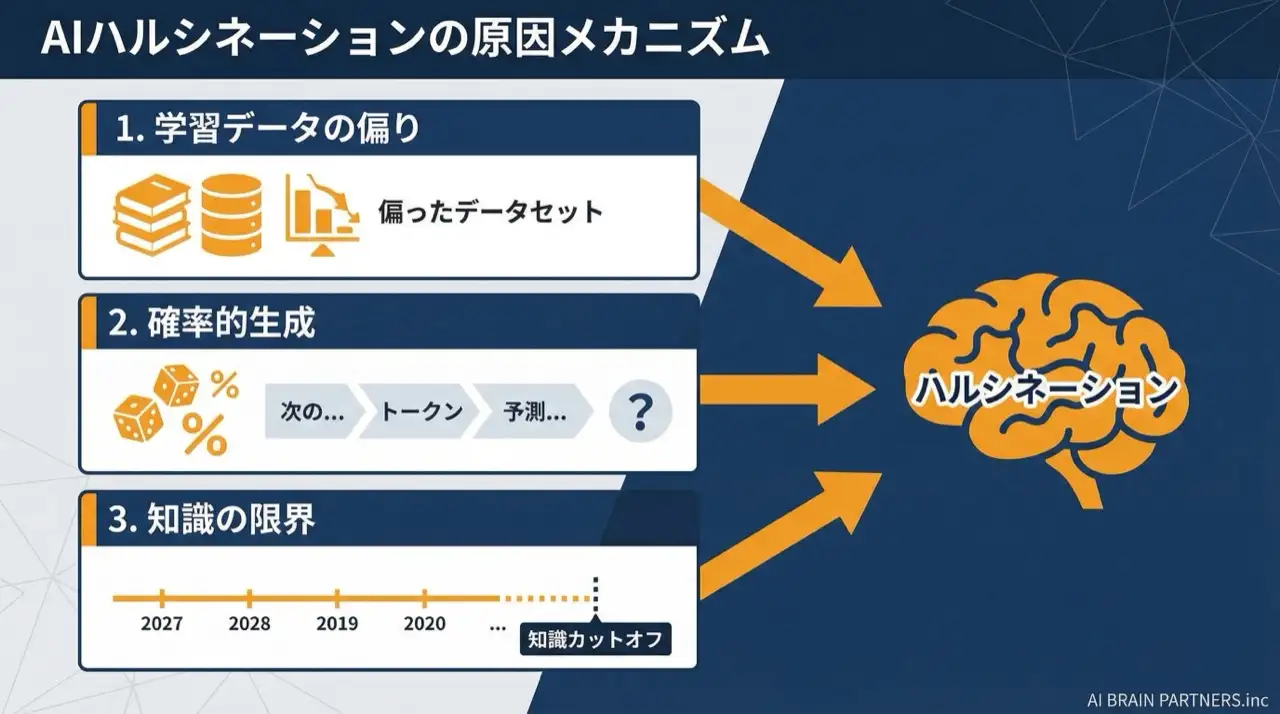
In other words, hallucination is not a model defect but a byproduct of a system optimized to produce natural-sounding text. That is why better models reduce it but never eliminate it.
The four types of hallucination
| Type | What happens | Example |
|---|---|---|
| Fact fabrication | Inventing facts that do not exist | "Tokyo Tower was built in 1920" (it was 1958) |
| Fact conflation | Mixing up separate facts | Attributing one person's achievement to another |
| Citation fabrication | Citing papers or books that do not exist | "According to Smith et al. (2023), 'AI Ethics Review'…" (no such paper exists) |
| Self-contradiction | Contradicting its own answer | "A has three elements: X, Y, Z, W" (says three, lists four) |
The most dangerous: fabricated citations
Of the four, citation fabrication is the most dangerous:
- It generates plausible author names, years, and titles
- It can even generate plausible-looking DOIs and URLs
- Without verification, it is indistinguishable from the real thing
Copy one into a report or proposal and you risk the source being exposed as nonexistent later — a serious blow to credibility. Always confirm that any citation actually exists.
Four mitigations
| Mitigation | Description |
|---|---|
| 1. Use RAG | Retrieve and reference external knowledge; answers can cite sources |
| 2. Ask specific questions | Avoid vague questions; be clear and concrete |
| 3. Chain of Thought | Instruct "think step by step" and surface the reasoning process |
| 4. Build a verification habit | Never take output at face value; always verify |
Among these, RAG (Retrieval-Augmented Generation) — having the model answer while consulting internal documents or trusted material — is especially effective for business use because it enables source-attributed answers. See What Is RAG? The 4-Step Pipeline and Vector Databases for details.
An anti-hallucination prompt
Simply making the handling of uncertainty explicit in your instructions dramatically improves resistance. Here is the example prompt from our course material:
Answer the question below.
Important instructions:
- If you are not confident, preface with "I'm not certain, but"
- If there is no source, state clearly "this needs verification"
- If you do not know, answer honestly "I don't know"
- If you are guessing, say explicitly "this is a guess"
Question: {user question}
How to live with hallucinations
Hallucination is a property, not a bug. The goal is not elimination but appropriate coexistence. Three practices matter:
- Verify — always check primary sources for important information; cross-check across multiple sources; confirm every citation exists
- Stay skeptical — keep asking "is that really true?"; the more confident the answer, the more caution it deserves; double-check specific numbers and dates
- Play to strengths — use AI where creativity matters more than accuracy: ideation, brainstorming, drafting and polishing text
Strengths vs. weaknesses
| Strong (hallucination rarely matters) | Weak (verification mandatory) |
|---|---|
| Ideation and brainstorming | Specific facts, figures, dates |
| Rewriting and proofreading | Citations of papers and books |
| Code scaffolding | Recent information (post-cutoff) |
| Summarizing and structuring | Specialized legal or medical knowledge |
"The more confident the answer, the more you should doubt it" — that is the baseline mindset for using generative AI at work. Writing this division of labor into your internal guidelines lets the whole team use AI safely. To train your team hands-on, see our corporate AI agent training.
Frequently asked questions
Q. What exactly is an AI hallucination? A. It is when an LLM generates information that is not grounded in fact but sounds plausible — citing nonexistent papers or describing fictional details with confidence. Crucially, this is not a bug but a structural property: LLMs generate text based on what makes a natural-sounding sentence, not on what is correct, so even the best models never eliminate it entirely.
Q. Why do LLMs hallucinate? A. Four main causes. First, LLMs generate from statistical patterns — which word tends to follow which — optimizing for naturalness rather than truth. Second, training data contains misinformation and ends at a knowledge cutoff. Third, models still tend to be optimized toward producing some answer rather than saying "I don't know," despite improvements from techniques like RLHF. Fourth, evaluation metrics often reward detailed, specific answers even when uncertain.
Q. Which type of hallucination is most dangerous? A. Citation fabrication. The model generates plausible author names, publication years, titles, and sometimes even DOIs and URLs for papers that do not exist — indistinguishable from real citations without verification. If copied into a report, the nonexistent source may be discovered later and damage your credibility. Make it a rule to confirm every citation's existence before use.
Q. How can we reduce hallucinations? A. Four mitigations work well: (1) use RAG so the model retrieves and cites external knowledge, (2) ask specific rather than vague questions, (3) instruct "think step by step" to surface the reasoning (Chain of Thought), and (4) build a habit of verifying output. Additionally, adding explicit instructions like "preface uncertain answers with 'I'm not certain'" and "say 'I don't know' when you don't know" measurably improves resistance.
Q. If hallucinations exist, is it dangerous to use AI at work? A. Not if you divide the work wisely. AI excels at tasks where creativity matters more than accuracy — ideation, brainstorming, drafting, rewriting, summarizing, code scaffolding. For specific facts, figures, dates, citations, recent information, and specialized legal or medical judgments, human verification must be mandatory. "Use AI in its areas of strength; verify in its areas of weakness" is the foundational operating model.
Related articles
- The Complete Guide to AI Agents for Business
- What Is RAG? The 4-Step Pipeline, Vector Databases & Use Cases
- Tokens and Context Windows Explained
- AI Agent Governance for Business
- Corporate AI Agent Training (hands-on)
Related services
Ready to put AI agents to work?
Turn what you just read into real workflows. AI Agent Camp helps non-technical professionals go from using to building — hands-on.
Last reviewed: 2026-06-10