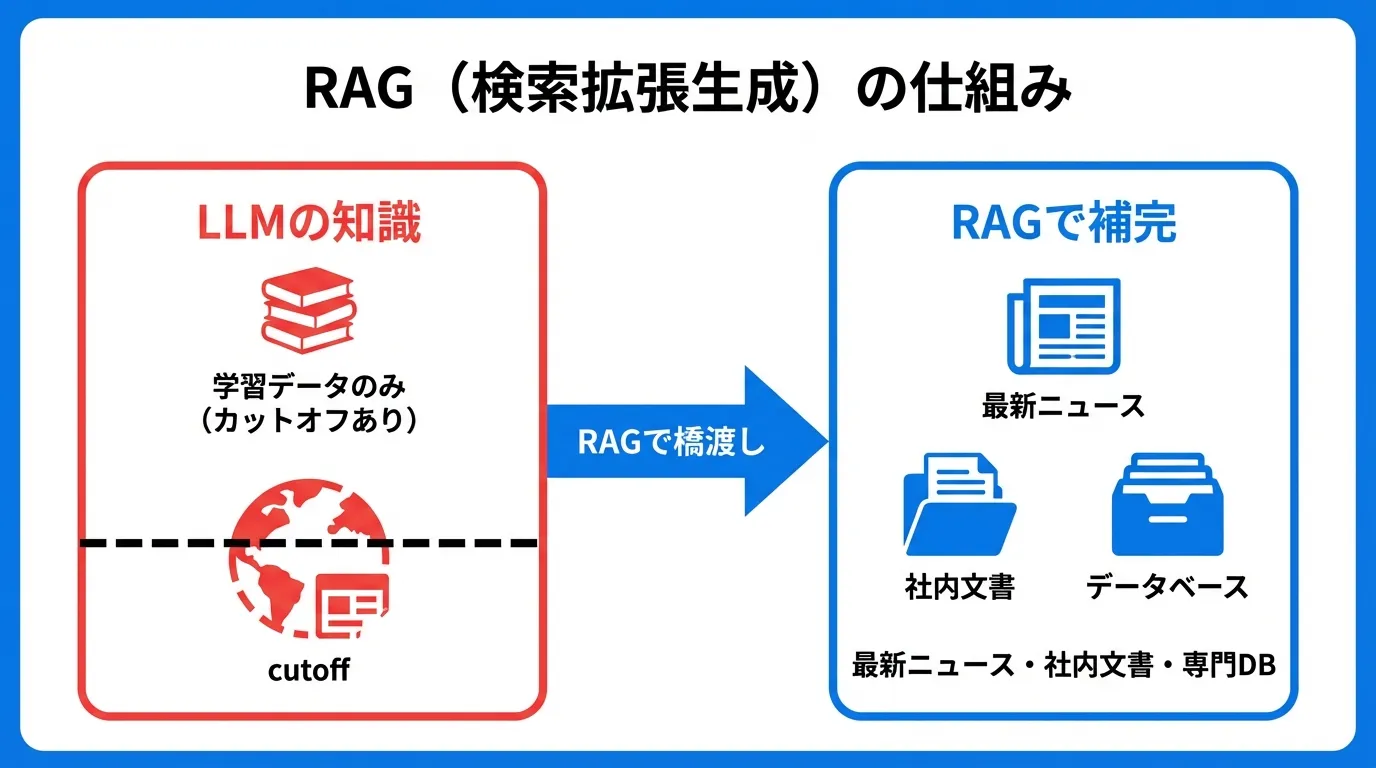
"ChatGPT can't answer questions about our internal policies." "We need the AI to ground its answers in the latest information and our own documents." Every organization that tries to put generative AI to work runs into this problem — and the answer is RAG.
This guide explains how RAG (Retrieval-Augmented Generation) works in four steps, covers its engine — the vector database — walks through advanced variants, and shows how to choose between RAG and fine-tuning. The content is based on the foundation lectures we use in our corporate training and online courses.
If you are new to AI agents in general, start with The Complete Guide to AI Agents for Business.
What you will learn
- What RAG is and why it matters (the four problems of an LLM without RAG)
- The four steps: Ingestion → Retrieval → Augmentation → Generation
- Vector databases — keyword search vs. semantic search
- A comparison of six major vector databases and a beginner recommendation
- Advanced variants: Agentic RAG, Hybrid RAG, Graph RAG, Multimodal RAG
- RAG vs. fine-tuning — clear decision criteria
- Business cases where RAG shines
What is RAG? An open-book exam
RAG (Retrieval-Augmented Generation) is a technique that augments an LLM's generation with information obtained through retrieval. The concept was first systematically proposed in the paper "Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks" (Lewis et al., 2020).
The best analogy is an open-book exam. A regular LLM takes the test relying only on memorized knowledge, but with RAG it can look up materials related to the question in a database and answer while reading them. That is why it can respond accurately about the latest information or internal documents the model never learned.
Four problems of an LLM without RAG
| Problem | Description |
|---|---|
| Knowledge cutoff | Knows nothing after its training data ends |
| Hallucination | Fabricates what it does not know |
| Private information | Internal documents were never in the training data |
| Hard to update | Adding new knowledge requires retraining |
RAG solves all four in reverse: fresh information arrives by simply updating the database, answers come with sources for better accuracy, internal documents become searchable, and it is far cheaper than retraining a model. For the structural causes of hallucination and how to counter them, see AI Hallucinations: Causes and Mitigations.
The four steps of RAG
RAG operates in four broad steps:
- Ingestion — the preparation stage: load your documents and convert them into vectors stored in a vector database
- Retrieval — fetch the information relevant to the user's question
- Augmentation — insert the retrieved results into the prompt
- Generation — the LLM produces an answer based on the augmented prompt
The key insight: the LLM itself is never modified. Only the information handed to the LLM (the context) changes. That is how your organization's proprietary knowledge becomes usable without any retraining. For the bigger picture of what goes into the context, see Tokens and Context Windows Explained.
Vector databases: the heart of RAG
The engine at the core of RAG is the vector database (Vector DB).
A conventional database searches by exact keywords — author name, publication date, and so on. A vector database instead searches by similarity of meaning. Search for "fun" and you also find "happy" and "delighted." This is semantic search.
| Aspect | Keyword search | Semantic search |
|---|---|---|
| Matching | Exact matches only | Hits words with similar meaning |
| Example | "dog" → only documents containing "dog" | "dog" → semantically related documents too |
| Mechanism | String matching | Distance in vector space (similar meanings sit close together) |
Comparing the major vector databases
| Database | Characteristics | Best for |
|---|---|---|
| Pinecone | Fully managed, fast, scalable | Production, large datasets |
| Chroma | Lightweight, runs locally, Python-friendly | Development and prototyping |
| Weaviate | GraphQL support, hybrid search | Complex queries |
| Milvus | Open source, high performance | Large-scale on-premises |
| Qdrant | Built in Rust, fast filtering, rich APIs | High-performance and filtered search |
| pgvector | PostgreSQL extension, operable with SQL | Adding to an existing PostgreSQL |
For beginners, Chroma is the recommended starting point: easy to try locally and immediately usable from Python. When moving to production, consider Pinecone or pgvector.
Advanced RAG variants
Once the basics are in place, four extensions are worth knowing:
| Variant | Overview | Strength |
|---|---|---|
| Agentic RAG | An AI agent plans and executes retrieval, running multiple searches autonomously and evaluating results | Handles complex questions |
| Hybrid RAG | Combines vector search with keyword search | Strong on proper nouns; better precision-recall balance |
| Graph RAG | Combines with a knowledge graph, exploiting relationships between entities | Strong on "how are A and B related?"; complex reasoning |
| Multimodal RAG | Indexes images and video alongside text | "Which products look like this image?"; charts inside documents |
A realistic path: get the basic four-step RAG running first, then adopt Hybrid if proper-noun retrieval struggles, or Graph if relationship questions dominate.
RAG vs. fine-tuning: how to choose
Both customize an LLM, but for different purposes. Fine-tuning means additionally training an existing model for a specific task or writing style.
| Aspect | RAG | Fine-tuning |
|---|---|---|
| Purpose | Reference external knowledge | Change the model's behavior |
| Ease of updates | Excellent — just update the DB | Limited — retraining required |
| Cost | Low | Historically high, though techniques like LoRA/QLoRA have reduced it substantially |
| Latency | Adds a retrieval step | No extra processing |
| Source attribution | Possible | Difficult |
| Best for | FAQs, document search, fresh information | Tone changes, domain specialization |
The decision criteria are simple:
- Need to reference fresh information or internal documents → RAG
- Need to cite sources → RAG
- Want to change how the AI talks or writes → fine-tuning
- Need both → combine them (fine-tuned model + RAG)
Where RAG delivers business value
- Internal document Q&A — answering questions about policies, manuals, and past cases
- Answers requiring up-to-date information — anything past the training cutoff
- Auditable answers with sources — "this answer is based on policy X"
- Frequently updated data — product info, price lists, FAQs with fast refresh cycles
The proven rollout pattern: start small with one document type (such as an internal FAQ), validate answer quality and source accuracy, then expand coverage. To get your whole team trained hands-on, see our corporate AI agent training.
Frequently asked questions
Q. What is RAG in one sentence? A. RAG (Retrieval-Augmented Generation) is a technique that retrieves information relevant to a question from an external database and uses it to augment the LLM's answer generation. It works like an open-book exam: the model answers while consulting reference material, so it can respond accurately even about fresh information or internal documents it never learned during training.
Q. Why can't a regular chatbot answer questions about our internal documents? A. Because an LLM's knowledge is limited to its training data (the knowledge cutoff). Private information such as internal policies or customer data was never part of training, and when asked about unknown topics the model risks fabricating answers (hallucination). With RAG, your documents are ingested into a vector database and the relevant passages are retrieved per question, so the AI can answer from your own knowledge base without retraining.
Q. How does a vector database differ from a regular database? A. The search mechanism. A regular database matches exact keywords, while a vector database converts text into numeric vectors and searches by similarity of meaning (semantic search). Searching "fun" also surfaces documents containing "happy." Because it finds related content even when the question's wording differs from the document's wording, it is essential to RAG's retrieval step.
Q. Should we use RAG or fine-tuning? A. Decide by purpose. If you need to reference fresh information or internal documents, or you need source attribution, choose RAG — knowledge updates only require a database refresh, and costs stay low. If you want to change the AI's tone, style, or domain-specific behavior itself, choose fine-tuning. If you need both, combining a fine-tuned model with RAG is a valid architecture.
Q. What is the smallest sensible way to start? A. Use a lightweight, prototype-friendly vector database such as Chroma, limit scope to one document type like an internal FAQ, and get the four-step pipeline working end to end. Have answers display their sources and verify the right documents are being referenced before expanding. Consider scale-ready options like Pinecone or pgvector when you move to production.
Related articles
- The Complete Guide to AI Agents for Business
- AI Hallucinations: Causes, Types, and Mitigations
- Tokens and Context Windows Explained
- Skills, SubAgents & Agent Teams
- Corporate AI Agent Training (hands-on)
Related services
Ready to put AI agents to work?
Turn what you just read into real workflows. AI Agent Camp helps non-technical professionals go from using to building — hands-on.
Last reviewed: 2026-06-10